过去一年,生成式 AI 赛道持续火热,到今天,“All in AI”已经成为几乎所有科技企业的共识,互联网企业在用 AI 重新打造业务和软件,终端厂商在用 AI 重塑产品,抢滩“AI 手机”、“AI PC”,上游的芯片和解决方案提供商,则也在用 AI 重新定义芯片。
在此背景下,作为很早就在底层芯片技术层面布局终端侧 AI 的高通,最近发布了《通过 NPU 和异构计算开启终端侧生成式 AI》白皮书。在这份白皮书中,高通详细解读了在生成式 AI 需求愈发旺盛的趋势下,他们是如何利用 NPU 和异构计算,开启终端侧的丰富生成式 AI 用例的。
异构计算满足生成式 AI 的多样化需求具体来说,高通的异构计算引擎也就是高通 AI 引擎,包含不同的处理器组件,分别是 CPU、GPU、NPU 以及高通传感器中枢等,他们共同协作以打造出色的体验,而在每一代产品上,高通都会不断升级上述所有组件的能力。
这其中,不同的处理器组件扮演不同的角色,各有擅长的处理任务。
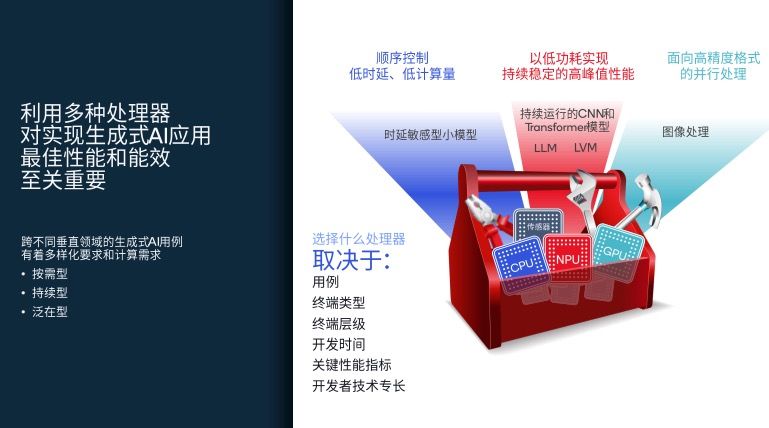
CPU 擅长顺序控制,非常适用于需要低时延的应用场景,因此高通会在对时延要求非常高的用例中使用 CPU。CPU 也适用于相对较小的传统模型,如卷积神经网络模型(CNN),或一些特定的大语言模型(LLM)。
此外 CPU 能力还取决于特定的产品类型。如果是传统的 PC 芯片,其 CPU 功能会十分强大;如果是车用芯片,则会更加注重 NPU 能力。
GPU 相信大家也比较清楚,主要擅长面向高精度格式的并行处理,比如对画质要求非常高的图像以及视频处理。
而 NPU,则主要是在持续型用例中,需要以低功耗实现持续稳定的高峰值性能,可以发挥其最大优势。
在基于 LLM 和大视觉模型(LVM)的不同用例,例如 Stable Diffusion 或其他扩散模型中,NPU 的每瓦特性能表现会十分出色。
高通表示,选择合适的处理器处理相关任务至关重要,但同时也要关注 SoC 整体的工作负载情况。例如你在玩一款重负载游戏,此时 GPU 会被完全占用,而如果是在浏览多个网页,CPU 可能会占用过高,此时 NPU 作为真正的 AI 专用引擎就会体现出非常大的优势,能够确保我们在 AI 用例中获得出色体验。
Hexagon NPU 的过去,现在和未来高通 AI 引擎中的 NPU,就是我们熟知的 Hexagon NPU,它拥有强大的差异化优势和业界领先的 AI 处理能力。
Hexagon NPU 的发展,也是一个长期演进,循序渐进的过程。
高通在 2015 年推出的第一代 AI 引擎时,其 Hexagon NPU 主要集成了标量和向量运算扩展,2016-2022 年之间,高通则将研究方向拓展至 AI 影像和视频处理,以实现增强的影像能力,同时他们还在这一时期引入 Transforme 层处理,并且在 NPU 中增加了张量运算核心(Tensor Core)。

从 2023 年开始,Hexagon NPU 实现了对 LLM 和 LVM 的支持,高通在 NPU 中增加了 Transformer 支持,以更好地处理基于 Transformer 的模型。现在,Hexagon NPU 能够在终端侧运行高达 100 亿参数的模型,无论是首个 token 的生成速度还是每秒生成 token 的速率,都处在业界领先水平。
此外,高通还引入了微切片推理技术,增加了能够支持所有引擎组件的大共享内存,以实现领先的 LLM 处理能力。
而接下来,Hexagon NPU 则会朝着对模态生成式 AI 的方向努力,比如在最近的 MWC 2024 上,高通展示了在终端上运行的多模态生成式 AI 模型,具体来说,是在第三代骁龙 8 上运行的首个大语言和视觉助理大模型(LLaVA),其能够基于图像输入解答用户的相关问题。这将为终端产品带来全新的能力,例如视障人士或将能够借助这样的功能在城市内进行导航,通过将图像信息转换成音频或语音,使得他们能够了解周围的事物。
同时,高通还在 MWC 上展示了基于骁龙 X Elite 计算平台、全球首个在终端侧运行的超过 70 亿参数的大型多模态语言模型(LMM),可接受文本和音频输入(如音乐、交通环境音频等),并基于音频内容生成多轮对话。
这也正是高通所寄予希望的未来发展方向,终端侧将能够处理丰富的感官信息,为用户带来完整的体验。
NPU 加持的异构计算,是这样完成 AI 应用需求的接下来,高通更进一步,解读了骁龙 Hexagon NPU 以及 AI 引擎整体的异构计算,是如何在具体的 AI 用例中工作、运行的。
在解读中,他们以第三代骁龙 8 移动平台为例,在该平台中全新的 Hexagon NPU 拥有 98% 的张量运算核心的峰值性能提升,同时标量和向量运算性能也得到了提升,并在 NPU 中集成了用于图像处理的分割网络(Segmentation Network)模块。
同时高通还增加了面向 AI 处理中非线性功能的硬件加速能力。凭借微切片推理技术,可以把一个神经网络层分割成多个小切片,可以在最多十层的深度上做融合,而市面上的其他 AI 引擎则必须要逐层进行推理。
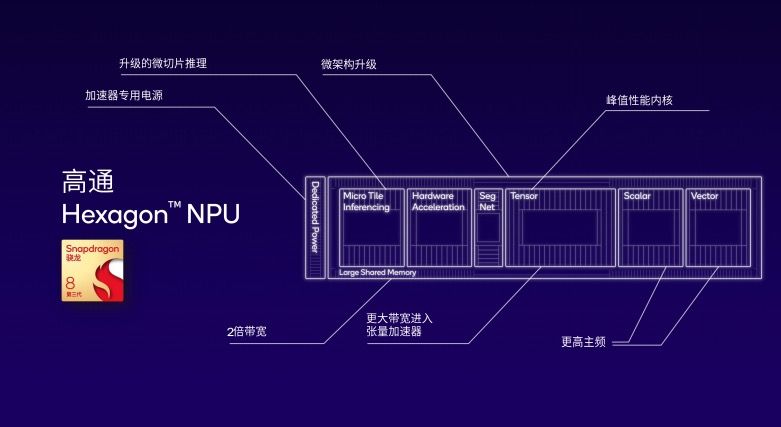
此外,第三代骁龙 8 的 Hexagon NPU 还拥有大共享内存,提供加速器专用电源传输轨道,也为大共享内存带来更大的带宽。
基于上述性能提升,高通打造了面向生成式 AI 处理的行业领先 NPU。
在具体用例中,高通以 AI 旅行助手为例,用户可以直接对模型提出规划旅游行程的需求。AI 助手能够立刻给到航班行程建议,并与用户进行语音对话调整行程,最后通过 Skyscanner 插件创建完整航班日程,给用户带来一步到位的使用体验。
在这个过程中,首先,用户的语音输入需要通过自动语音识别(ASR)模型 Whisper 转化为文本,Whisper 是 OpenAI 发布的一个约 2.4 亿参数的模型,它主要在高通传感器中枢上运行。
接下来利用 Llama 2 或百川大语言模型基于文本内容生成文本回复,这一模型在 Hexagon NPU 上运行。之后需要通过在 CPU 上运行的开源 TTS(Text to Speech)模型将文本转化为语音。
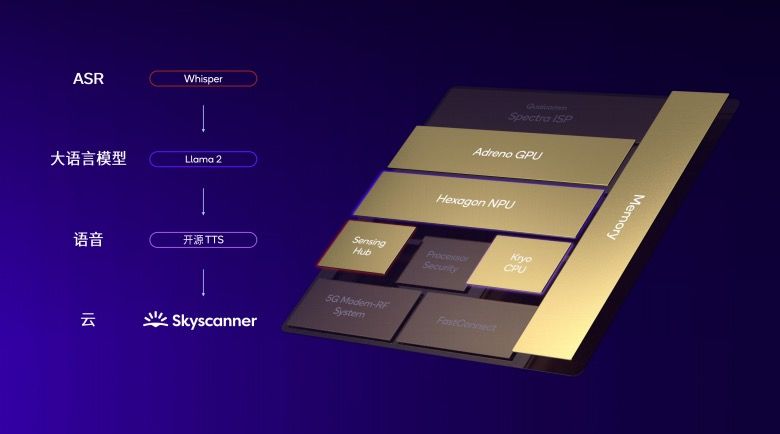
最后,通过高通的调制解调器技术进行网络连接,使用 Skyscanner 插件完成订票操作。这一流程展示了如何通过选择合适的处理器进行异构计算,并最终形成完整的使用体验。
在上述所有的硬件 AI 能力之上,高通还打造了高通 AI 软件栈(Qualcomm AI Stack)。它能够支持目前所有的主流 AI 框架,包括 TensorFlow、PyTorch、ONNX、Keras;它还支持所有主流的 AI runtime,包括 DirectML、TFLite、ONNX Runtime、ExecuTorch,以及支持不同的编译器、数学库等 AI 工具。
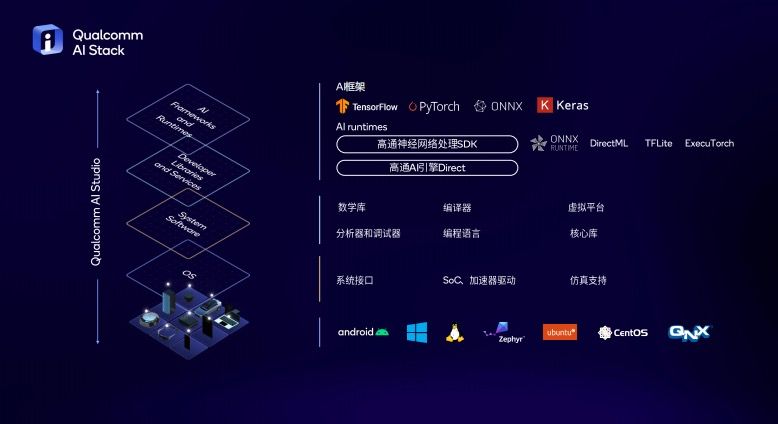
此外他们还推出了 Qualcomm AI studio,为开发者提供开发过程中需要用到的相关工具,其中包括支持模型量化和压缩的高通 AI 模型增效工具包(AIMET),能够让模型运行更加高效。高通 AI 软件栈是当前边缘侧的业界领先解决方案。
正是基于高通 AI 软件栈和核心硬件 IP,高通才能跨过所有不同产品线,将应用规模化扩展到不同类型的终端,从智能手机到 PC、物联网终端、汽车等等。这无疑为其合作伙伴以及用户带来显著优势,开发一次就能覆盖高通不同芯片组解决方案的不同产品和细分领域进行部署。

总体来说,通过这份生成式 AI 的白皮书,我们能够看到高通在终端侧生成式 AI 的全链路部署、Hexagon NPU 在终端侧生成式 AI 方面展现出的领先实力及其背后丰富的技术细节。可以说,利用多种处理器进行异构计算,特别是 NPU 的表现,对于实现生成式 AI 应用最佳性能和能效至关重要,同时,终端侧 AI 正成为全行业关注的焦点,其在成本、能效、可靠性、安全性等方面的优势都可以成为云端 AI 的绝佳拍档,而高通在终端侧生成式 AI 方面已经有着多年的积累,并展现出领先的技术领导力和出色的生态系统建设成果,相信他们能够在未来持续通过产品技术和生态合作,真正赋能终端侧生成式 AI 的规模化扩展。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com