
撰文 | 田小梦
编辑 | 李信马
题图 | 谷歌I/O大会直播截图
一天前OpenAI抢发的GPT-4o大模型,让沉寂多时的AI又燥热起来。当然,作为“吃瓜群众”,在关心OpenAI的同时,我们更想看看今年夹在OpenAI与微软中间发布的谷歌,将如何反击。
此前谷歌已经表明,今年的I/O大会将全部围绕人工智能展开。因此,当Alphabet 首席执行官桑达尔·皮查伊 (Sundar Pichai)站上舞台时,这场“攻防赛”就正式拉开帷幕。
在长达 110 分钟的Keynote中,谷歌就提及了120次人工智能。不难看出,面对竞争对手,谷歌存在焦虑,亟需在这场“肌肉秀”中展示出自己的AI能力。

图片来源:谷歌I/O大会直播截图
·Google将Gemini 1.5 Pro上下文窗口扩展到了200万个tokens;
·升级后的 Gemini Advanced可以支持35多种语言和150多个国家/地区;
·Gemini 1.5 Flash的价格定为每100万个token 35美分;
·Gemini 1.5 Flash针对低延迟和成本等重要的任务进行了优化;
·Gemma 2采用全新架构,实现突破性的性能和效率,并将提供27B大小的尺寸;
·基于PaLI-3,推出第一个视觉语言开放模型 PaliGemma;
·Gemini 正在“成为 Android新的人工智能助手”;
·第六代TPU Trillium发布,与上一代TPU v5e相比,每个芯片的计算性能提高了4.7倍;
除此之外,谷歌推出的视频生成模型——Veo和移动对话助理性产品Gmini Live,对标OpenAI的Sora和GPT-4o模型,可以说火药味十足。
正式进入Gemini时代
当皮查伊站在舞台中央时,他先强调道:“我们仍处于人工智能平台转变的早期阶段。对于创作者、开发者、初创公司和每个人来说,我们看到了巨大的机遇。”
转言之间,直接奔入主题称:“我们希望每个人都能从Gemini所做的事情中受益。”目前,有超过150万开发者在使用Gemini做开发,Gemini最近三个月时间达到了100万订阅用户。

图片来源:谷歌I/O大会直播截图
首先,皮查伊宣布了Gemini 1.5 Pro的更新。
Gemini 1.5 Pro的优势在于超长的上下文窗口,在今年2月发布时,达到了100 万个tokens,超过了所有的大语言模型。而在今天,谷歌进一步拓展它的能力,将上下文窗口扩展到200万个token,现在已经将试用版开放给开发者。

图片来源:谷歌I/O大会直播截图
在模型性能上,Gemini 1.5 Pro 对一些关键用例进行了质量改进,例如翻译、编码、推理等,可以处理更广泛、更复杂的任务。在指令上,Gemini 1.5 Pro现在可以遵循越来越复杂和细微的指令,包括那些指定产品级行为(如角色、格式和风格)的指令,也可以让用户能够通过设置系统指令来控制模型行为。
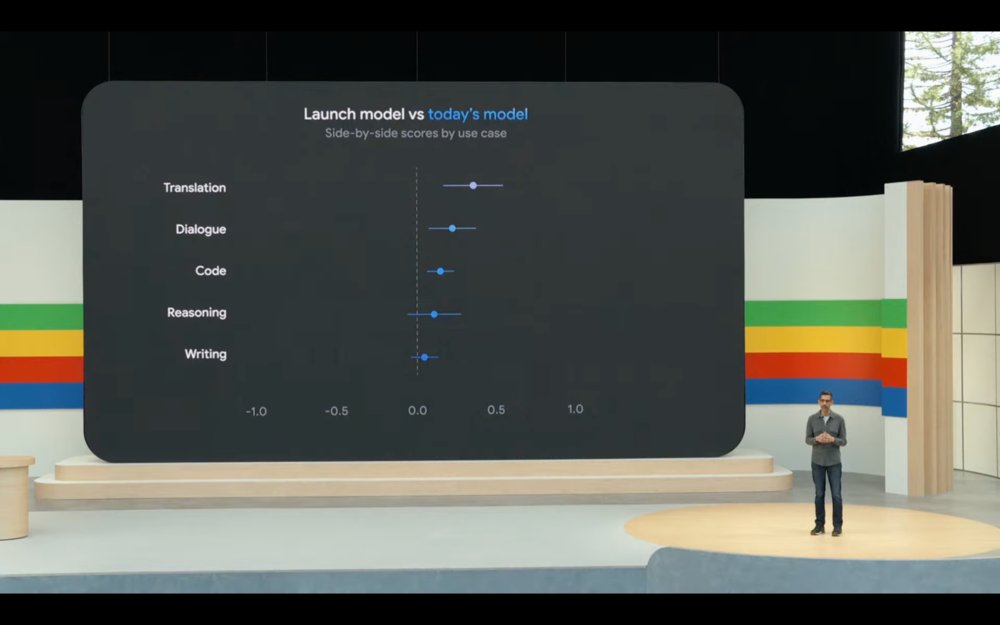
图片来源:谷歌I/O大会直播截图
Gemini 1.5 Flash,这是一款专为扩展而打造的轻量级型号,也是 API 中速度最快的 Gemini 型号。它针对低延迟和成本最重要的任务进行了优化,服务成本效益更高,并具有突破性的长上下文窗口。
值得一提的是,此次大会谷歌还宣布推出基于Gemini 1.5 Pro的Gemini Advanced。升级后的Gemini Advanced可以处理“多个大型文档,总计最多 1500 页,或汇总100 封电子邮件”,支持35多种语言和150多个国家/地区。

图片来源:谷歌I/O大会直播截图
紧接着发布的是比 Gemini 1.5 Pro 更轻、更便宜的模型——Gemini 1.5 Flash。虽然“轻”,但Flash功能丝毫不逊色。默认情况下,Flash 具有100万个token 上下文窗口,擅长做摘要、聊天、图像和视频字幕、从长文档和表格中提取数据等。

图片来源:谷歌I/O大会直播截图
谷歌表示,这是通过“distillation”(蒸馏)的方式来实现的,将 Gemini 1.5 Pro 中最重要的知识和技能转移到较小的模型中。
Gemini 1.5 Flash的价格定为每100万个token 35美分,与GPT-4o的每100 万个token 5美元的价格相比低廉许多,也把硝烟烧的更旺起来。

图片来源:谷歌I/O大会直播截图
除上面的产品外,让现场掌声不断地便是AI Agent,通过Project Astra看到了谷歌对OpenAI的隔空喊话。
Agent框架需要像人类一样理解和响应复杂多变的世界——并且记住它看到和听到的内容,以理解上下文并采取行动。Project Astra 则类似一款以取景器作为主界面的应用程序。

图片来源:谷歌I/O大会直播截图
谷歌在发布会上展示了一个人拿着手机,将摄像头对准办公室的各个地方,并用语言与其交互的场景。
在召唤Gemini之后,测试者提出问题:“当你看到会发出声音的东西时,告诉我。”它回复称:“我看到一个扬声器,它可能会发声。”
接下来,测试者用红色剪头指向扬声器的顶部,再次问道:“这个扬声器的部件叫什么?”Gemini答出:“这是高音扬声器,能产生高频的声音。”
这些还都是开胃小菜,意想不到是它还能读懂代码,而且“记忆力”十足。
测试者问Gemini:“你记得在哪里见过我的眼镜?”
Gemini:“是的,我记得。你的眼镜就在桌子上,旁边有一个红苹果。”
除核心模型更新外,谷歌还宣布了开源模型Gemma的2.0版本,将于 6 月推出。据介绍,它具有 270 亿个参数,其性能可与 Llama 3 70B 相媲美,但尺寸却只有 Llama 3 70B 的一半,它的高效设计使其所需的计算量少于同类模型的一半。
还发布了自家首个视觉-语言开源模型——PaliGemma,专门针对图像标注、视觉问答及其他图像标签化任务进行了优化。

图片来源:谷歌I/O大会直播截图
发布“谷歌版Sora”
在文生视频、文生图方面,谷歌也作出了相应的产品升级和发布。
其中,谷歌在推出的视频生成模型 Veo,可以视为对标OpenAI的Sora。

图片来源:谷歌I/O大会直播截图
据Demis Hassabis介绍,Veo可以制作“高质量”1080p视频,时间可以超过一分钟。Veo 具有“对自然语言和视觉语义的高级理解”,可以创建用户想要的任何视频。Veo 还能够理解电影和视觉技术,例如延时拍摄的概念。
从今天开始,谷歌会为一些创作者在VideoFX中提供预览版Veo,创作者可以加入谷歌的waitlist。谷歌还将把Veo的一些功能引入YouTube Shorts等产品。
Imagen 3则是最新的文本到图像框架。比起上一代,Imagen 3能够生成更多细节、光影丰富,且干扰伪影更少的图像。

图片来源:谷歌I/O大会直播截图
此外,谷歌特别就图像生成中文字模糊的问题进行了改进,即优化了图像渲染,使生成图像中文字清晰并风格化,生成高质量的图像。
为了提高可用性,Imagen 3将提供多个版本,每个版本都针对不同类型的任务进行了优化。
必争之地AI搜索,更智能的Gemini体验
除大模型间的比拼外,最令人关心的还有谷歌的搜索。
在发布会上,Google 发布了一个名为“AI 概述”(AI Overviews)的功能,但仅限美国,其他国家还需要等待。

图片来源:谷歌I/O大会直播截图
从展示来看,用户将能够通过简化语言或更详细地分解来调整AI搜索结果概述;其次借助 Gemini的多步推理能力,AI搜索可以一次性处理复杂的多步,乃至多问题;再者在多步推理能力之上构建了AI搜索的计划能力,即通过AI搜索中的计划功能,可以直接在搜索里获得一个完整的计划;最后是灵感延展功能,AI搜索在创建一个AI组织的结果页面,使用户更容易探索。
同时靠Gemini的多模态功能,谷歌可以做到利用声音搜歌曲,利用图片搜产品。甚至可以用Circle to Secarch 功能圈出图片中的一部分去搜索。
值得一提的是,谷歌还引入了一个新的转折点——视频。Gemini会让用户上传演示其要解决的问题的视频,然后启动搜索在论坛和互联网的其他区域以找到解决方案。
谷歌演示到,如用户在旧货店买了一台唱片机,但打开时无法工作,带有针头的金属部件在意外漂移。用视频搜索能节省了用户找到合适词语来描述这个问题的时间和麻烦。
除将Gemini能力加持到搜索引擎外,Gemini还将为Gmail应用程序提供一些有趣的新功能,包括长电子邮件线程的摘要。用户还可以直接与 Gemini聊天,从整个收件箱中查找详细信息。
当然,与Gemini的互动应该是对话式的、直观的。谷歌还宣布推出称为 Live 的全新 Gemini体验,让用户可以使用语音与 Gemini 进行深入对话。用户甚至可以按照自己的节奏说话或在回答中途打断以提出澄清问题。而且今年晚些时候,将能够在上线时使用摄像头,开启关于周围所见内容的对话。

图片来源:谷歌I/O大会直播截图
在系统落地上,谷歌宣布对其适用于Android设备的Gemini AI聊天机器人进行一些改进:Gemini正在“成为Android上新的人工智能助手”。借助 Gemini Nano,Android 用户可以快速体验 AI 功能。
谷歌还透露道,从今年晚些时候的 Pixel开始,其将推出最新型号Gemini Nano 与多模态。这意味着新版 Pixel 手机不仅能够处理文本输入,还能够理解更多上下文信息,例如视觉、声音和口语。
AI时代的基础设施——Trillium
算力是AI时代必不可少的要素之一。在这次发布会上,谷歌发布了第六代 TPU—— Trillium。

图片来源:谷歌I/O大会直播截图
Trillium 是谷歌迄今为止性能最强、效率最高的 TPU,与上一代 TPU v5e 相比,每个芯片的计算性能提高了 4.7 倍。据悉,将在 2024 年底向 Cloud 客户提供 Trillium。

图片来源:谷歌I/O大会直播截图
此外,Trillium 配备了第三代 SparseCore,这是一种专门用于处理超大嵌入的加速器,常见于先进的排序和推荐工作负载中。Trillium TPU 使训练下一波基础模型更快,并以更低的延迟和更低的成本服务这些模型。
另外,能耗上Trillium TPU 比 TPU v5e 的能源效率提高了 67% 以上。
以上内容,是此次发布会的重点内容。整体来看,谷歌在AI领域仍处于不断整合的过程中,无论是搜索还是全家桶产品,正如皮查伊最开始说的“我们仍处于人工智能平台转变的早期阶段”,未来还有很长的路要走。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com