近日,DeepMind的AlphaProof/AlphaGeo在国际数学奥林匹克竞赛(IMO)中取得了前所未有的成绩,解出了六道问题中的四道获得银牌。这一成就无疑将与“深蓝”击败卡斯帕罗夫和“AlphaGo”击败李世石一样,成为人工智能挑战人类智力巅峰的又一里程碑,同时也将引发新一轮关于机器智力边界的讨论。
通过分析本次国际数学奥林匹克竞赛(IMO)各题目的解题表现,我们可以清晰地看到不同算法如何提升和补充了人工智能模型的能力。
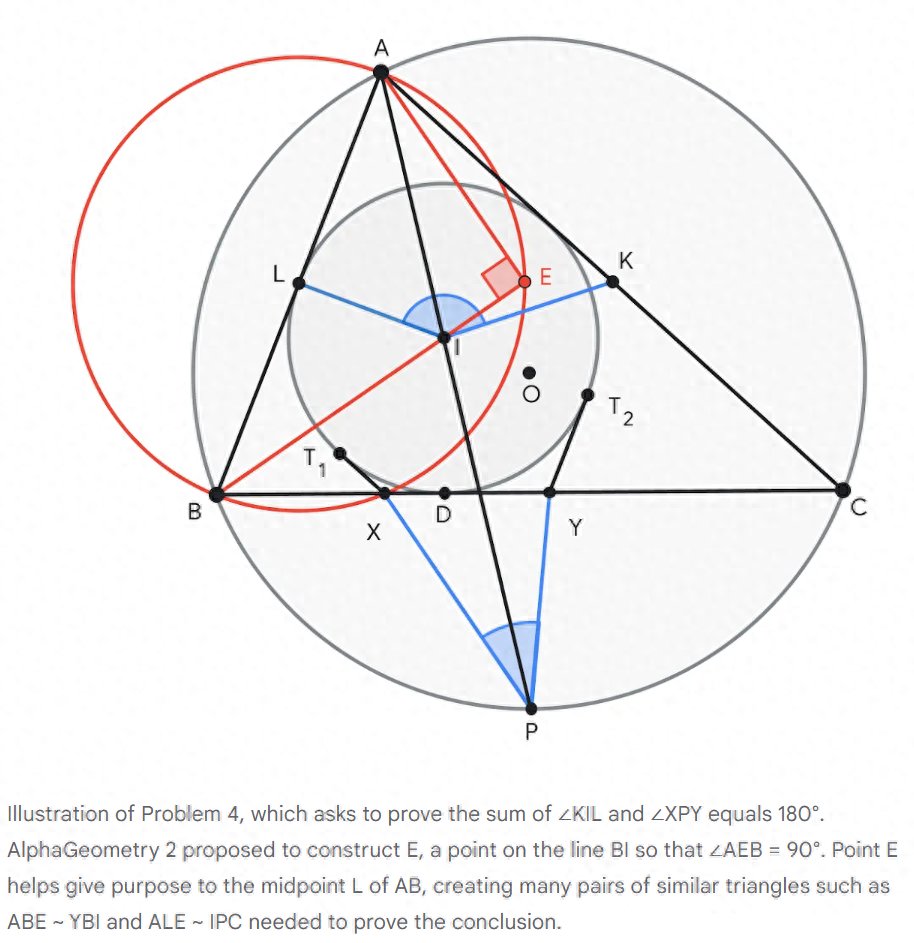
Q4作为一道典型的几何题,展示了DeepMind今年早些时候发布的AlphaGeo算法的能力。与更为通用的AlphaProof不同,AlphaGeo专注于通过几何题引擎和辅助线解决几何问题。它通过建立一个包含一亿条复杂命题证明的庞大数据库,培养了神经网络判断辅助线效用的能力。这个理解辅助线功效的神经网络能够从数十条可行的辅助线中筛选出最具潜力的方向。这种高效筛选使AlphaGeo能在搜索树上深入探索,从而解决更具挑战性的问题。由于几何题的搜索空间最小,AlphaGeo在拿到题后19秒就证明出来了,远快于任何人类。(图为AlphaGeo的解法和辅助线)
Q2则考验了“中间命题”的广度。与几何题不同,数论问题的中间步骤搜索空间更为广阔。在Q2中,如果参赛者(无论是人类还是AI)能洞察到x=ab+1这个巧妙的中间步骤,整个问题就会简化为仅需三行即可证明的简单命题。这意味着,AlphaProof与人类一样,需要具备发现x=ab+1的洞察力。考虑到这个构造在已知题库中前所未见,对它的洞察力必然源于AlphaProof在生成数十亿训练样本的过程中,反复尝试类似问题后产生的涌现能力。

Q1和Q6则考验了AI反复创造和验证个例的能力。具备这种能力的AI可以基于已知命题生成大量个例,通过验证这些个例是否符合证明条件,不断探索正例和反例的边界,最终找到正确的命题。这种主动探索能力的出现,预示着AI有能力在寻找未知解时探索新颖路径,并在过程中不断调整方向。最令人惊叹的是,在这次比赛中,只有五名人类选手解出的Q6,AlphaProof却给出了满分证明。这有力地证明了AI在某些方面已经超越了人类的通用推理能力。


然而,AI未能解出的Q3和Q5,都属于奥数中的“排列组合”问题。这类问题的特点是解空间极其发散,且命题相对更加开放。这导致AlphaProof在构建人造题库时难以进行更深入的搜索,从而限制了它在这类问题上的解题能力上限。这不仅展示了AI在数学推理方面的巨大进步,也揭示了它在解空间更广的领域存在的局限性,为未来AI算法的改进指明了方向。


按照IMO规则,6道题目每道题可获得7分,总分最高为42分。DeepMind系统最终获得了28分,每个问题都得到了满分,相当于银牌组的最高分。2024年的金奖门槛从29分开始,在正式比赛中,609名参赛者中有58人获得了金奖。
(齐鲁晚报·齐鲁壹点客户端编辑 武秀英 综合 、IT之家)
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com