电商APP中,搜索模块是如何把控搜索结果,以保证搜索结果符合用户搜索意图?这篇文章里,作者介绍并梳理了电商搜索中的类目预测和相关性控制模块,一起来看看,或许可以帮助你更了解电商搜索。

一、引入
用户在电商APP上进行搜索时,搜索引擎是如何把控返回的搜索结果是符合用户搜索意图的了?
电商搜索结果的相关性把控一般是通过两种方法:一种是通过类目相关性来把控,一种是通过相关性控制模型来把控。但相关性把控的尺度是没有标准答案的,在满足平台整体业务特性和用户体验的前提下,可以基于用户个性化的偏好进行进一步的相关性阈值控制。用户个性化偏好的了解既可以通过系统的EE(探索与利用)机制,又可以通过调研问卷的形式来让用户主动反馈。
下面详细介绍一下电商搜索中的类目预测和相关性控制模块:
二、类目预测
1. 引入不管是电商领域的搜索还是内容社区领域的搜索,全都需要做类目预测,电商和内容社区都有自己专门的类目分类体系。类目预测有助于更好地计算检索词与物料之间的相关 性,并应用到后续搜索类目导航功能中。
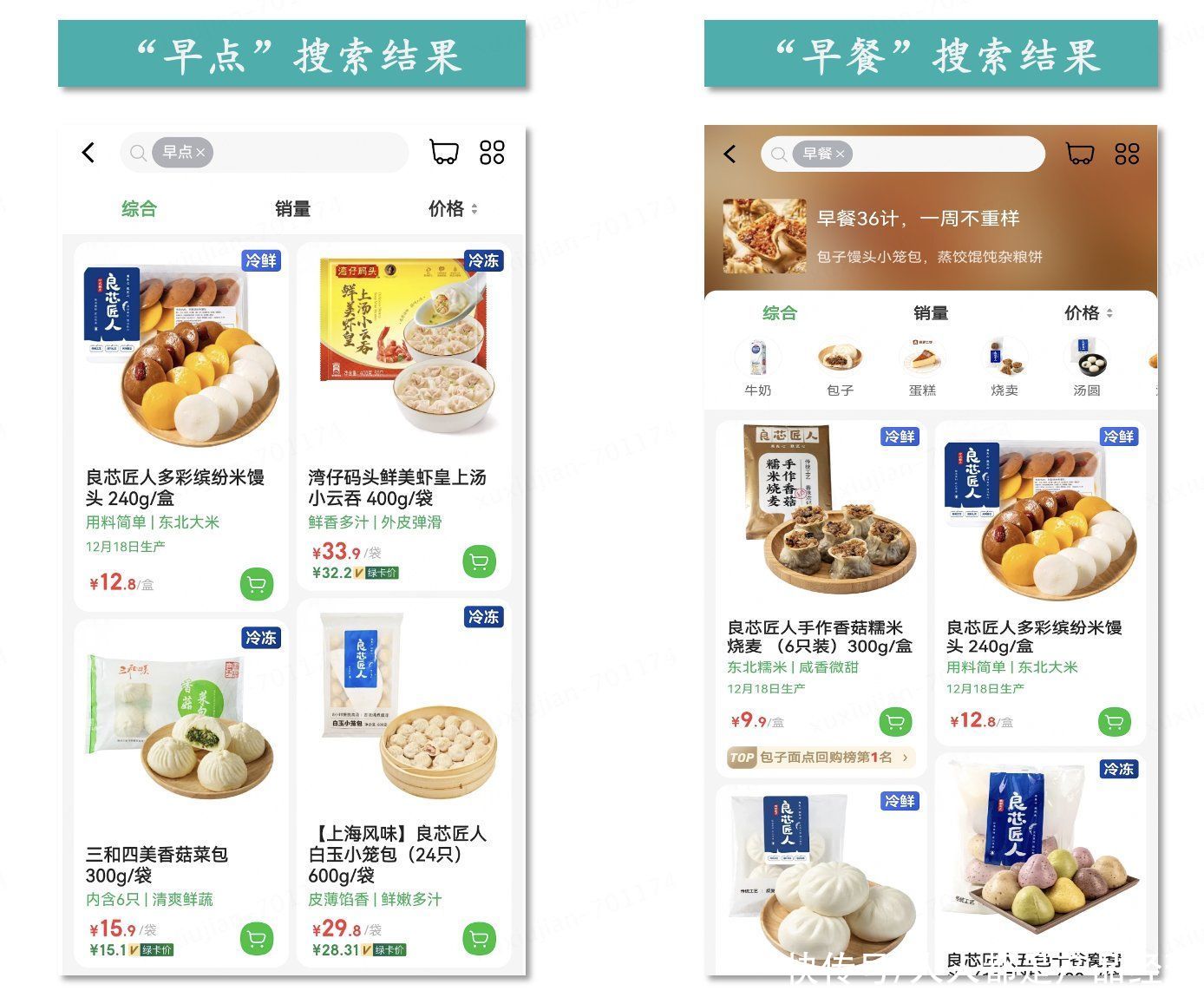
比如用户在生鲜电商平台叮咚买菜搜索“早点” 和“早餐”时,结果如下图所示,搜索引擎将“早点”“早餐”和牛奶、包子、烧卖、汤圆等类目关联起来,其实就是类目预测模块将原始检索词与这些类目关联起来。类目预测的另一个作用是在后续相关性排序环节中,将关联度更高的类目物料排在前列。
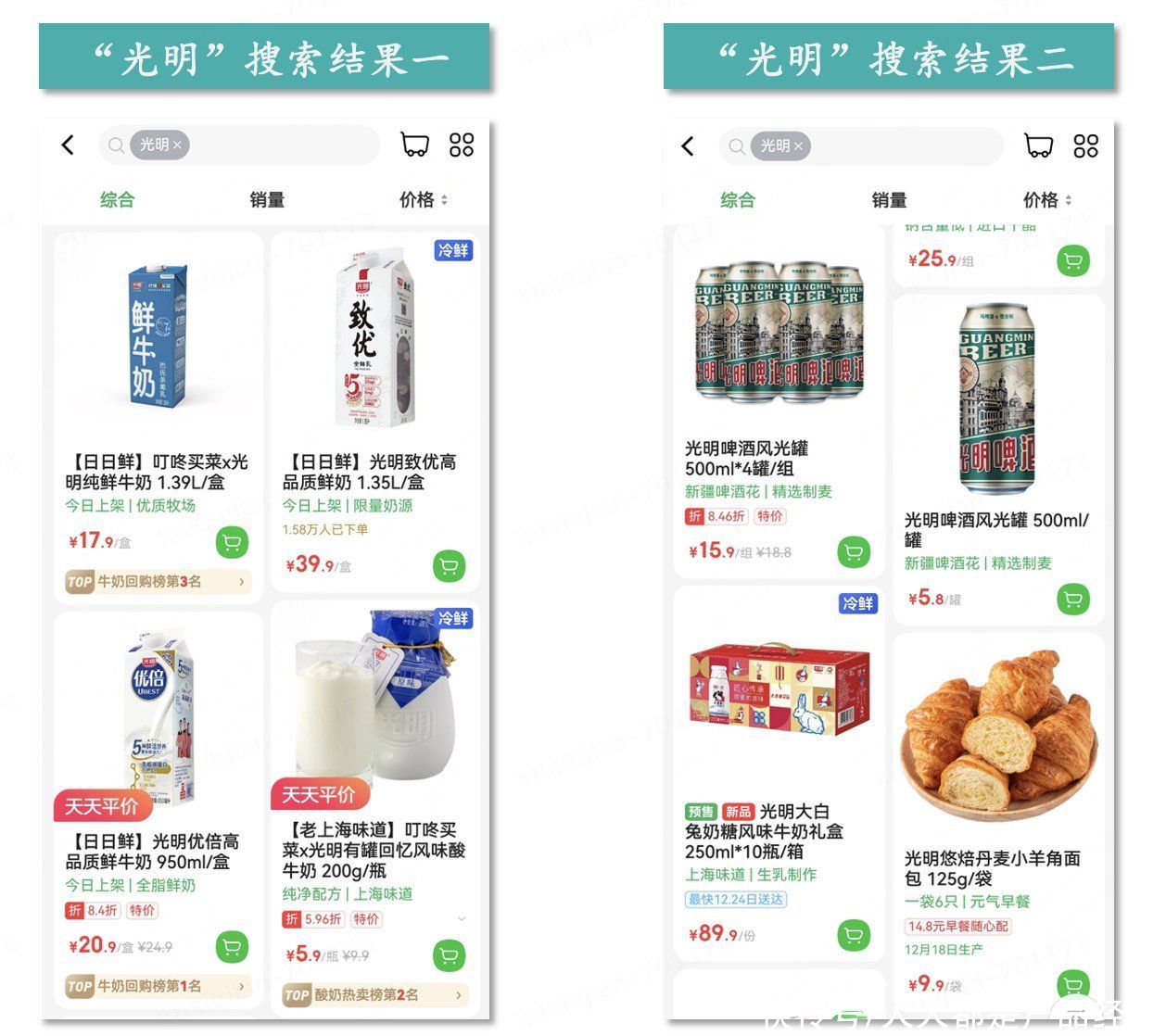
如下图所示, 能与“光明”匹配的类目有很多,比如牛奶、啤酒、大米和面包等,我们需要通过类目预测推测“光明”和哪一个类目的关联度最高,以便在排序的时候进行参考。模型预测出“光明”和牛奶类目的关联度最高,所以在后续排序中就需要将牛奶排在前列。
 2. 类目预测方法
2. 类目预测方法常见的类目预测有三种方法。
1)基于人工规则
通过日志信息将热门的检索词提取出来,然后通过人工将这些检索词和相关类目匹配起来,保证用户下一次搜索时与检索词匹配的类目是正确的。
- 优点:可以实现快速上线。
- 缺点:可拓展性较差,人工运营成本很高。 在搜索引擎搭建的初期可以使用此种方法。
2)基于用户行为的数据统计
第二种方法是通过用户的行为数据来分析得出每一个检索词对应的类目。
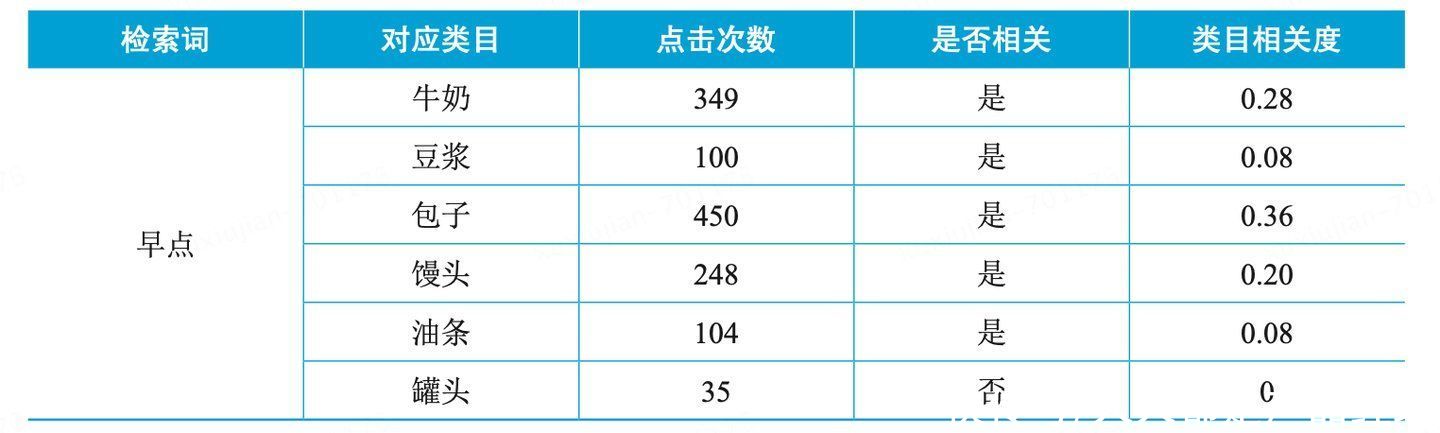
首先统计每一个检索词被搜索后,用户点击并浏览的物料对应的类目分布。用户会主动寻找搜索结果里面的正确答案,用户点击浏览的物料对应的类目就是该检索词应该匹配的类目。我们需要设计一个指标阈值,指标是单位时间内检索词对应单个类目的点击量,点击量大于阈值才代表该数据是可信的。
如下表所示,假设将点击次数阈值设置为50次,则罐头类目和检索词“早点”之间的相关度为0,其他类目与检索词的相关度可以用类目点击次数除以总点击次数来计算。
- 优点:利用了用户的历史行为数据,可以从数据中进行学习,具有一定的拓展性。
- 缺点:对于长尾检索词的覆盖度较低。
3)基于类目预测模型
上面介绍的两种方法对于新检索词的类目预测覆盖度都很低,拓展性也一般。实际工作中,我们需要构建专门的类目预测模型。下面本书以电商领域的类目预测为例进行说明。
① 训练样本构建
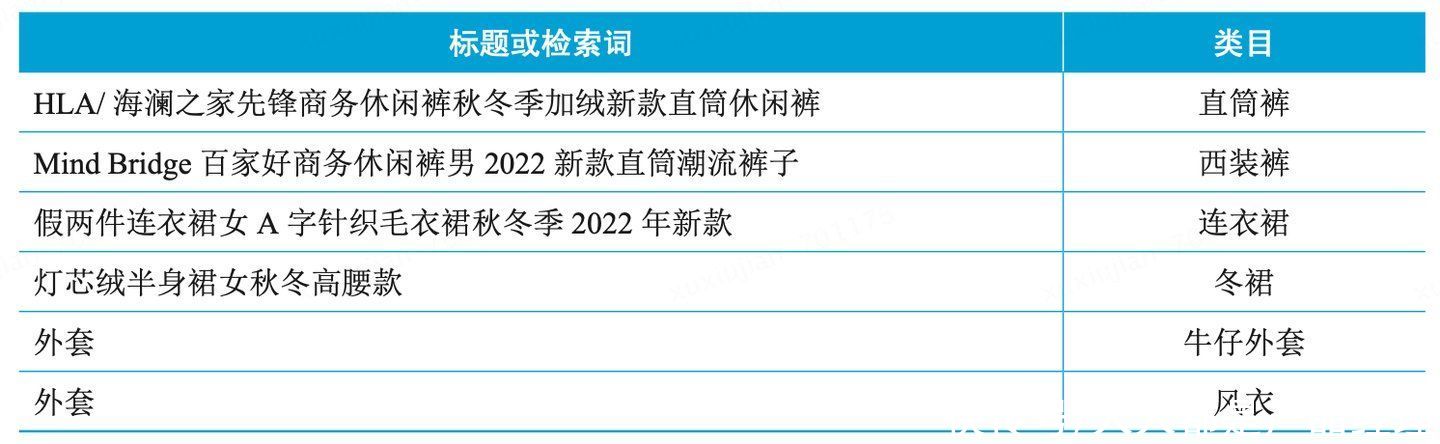
构建类目预测模型的第一步是构建训练样本,在电商领域,我们可以将商品标题或用 户历史检索词与对应的类目构成一对,一对代表一条训练样本。如下表所示,构建相应的训练样本,并进行人工标注和二次审核。类目预测模型是 一个多分类模型,一个检索词可能对应多个类目。
② 预测结果的选择
模型的输入为检索词,输出为可能相关的类目及对应的概率。因为类目预测模型是一个多分类模型,所以单个检索词可能会输出多个相关类目。此时我们需要针对类目预测的相关性设置一个阈值,比如检索词与类目的预测相关性超过 0.5 才说明两者之间的相关性可信。这个阈值需要根据实际训练出的模型在测试集上的验证效果进行确定。
③ 实际应用
实际应用时,我们一般会将类目预测模型分为线上和线下两部分。因为线上模型对实时性要求非常高,所以我们将一部分类目预测工作放在线下进行。因为每天搜索引擎里面80% 以上的搜索都是重复性搜索,针对这部分检索词可以提前进行类目预测,并通过人工方式对预估错误的检索词进行纠正,最终将类目预测结果提前存储到 Redis 内存数据库中,线上使用时直接查询即可。针对另外 20% 的长尾检索词,可进行线上实时预测。通 过此种方式可以大大减轻线上的系统压力。
- 优点:泛化性强,对于长尾检索词,类目预测的准确率很高。
- 缺点:线上模型耗时较多,需要设计合理的系统架构。
三、相关性控制
除了上述介绍的类目预测模型,在部分召回分支里比如语义相关性召回策略里,针对召回的结果还会单独再过一个相关性控制模型,去评估搜索结果和Query之间的相关性,针对相关性较弱的搜索结果进行过滤。
因为语义相关性召回从语义层面评估Query和文档的相关性,很多召回的物料在文本层面和检索词不具备任何相关性,所以实际应用时会出现相应的用户体验问题。
为了尽量减少线上出现的用户体验问题,系统里就需要单独设计一个相关性控制模型。相关性控制模型是一个二分类模型,专门针对向量召回的物料进行判断,评估其和检索词是否相关。
1. 相关性控制模型与语义相关性召回模型的差异第一处是语义相关性召回模型输出的是检索词与文档的相似度,是一个具体数值,而不是类别。相关性控制模型输出的是类别,即相关或不相关。
第二处是语义相关性召回模型训练时使用的核心数据来自线上点击曝光数据,而相关性控制模型训练时使用的数据主要是人工标注数据,需要确保检索词与文档的严格相关性。
2. 工业界实际应用部分公司将相关性控制模型和语义相关性召回模型所需完成的任务合二为一,全部由语义相关性召回模型完成。
首先,对语义相关性召回模型使用的训练样本进行人工审核, 确保训练样本的严格相关性。其次,系统对语义相关性召回模型最终产出的相似度设置一个较高的阈值,保证返回的物料相关性很高。
模型拆分以后各端可以专注于优化自己的核心目标,模型融合在一起后既要保证高相关性,又要保证召回较多的物料,这两个优化目标在某种层面上是相悖的。具体是否进行拆分,视公司搜索引擎的发展阶段和实际业务量 而定,目前头部互联网公司都将这两个模型拆分开,分别进行优化。
四、用户对于“精准度“的个性化偏好
之前提到过,不同用户对于“精准度”的偏好是不一样的,有些用户希望搜索结果就是和自己搜索词强关联的结果,有些用户可以接受搜索结果中出现一些没有那些精准的结果。
如何去了解不同用户的偏好进而去更好的满足用户的不同需求?一种方式可以通过系统探索,去试探用户的兴趣。另一种就是像淘宝这样,可以通过调研问卷,让用户来主动反馈,最终基于用户的反馈来把控搜索结果的精准度。

本篇文章节选自我的新书《搜广推策略产品经理-互联网大厂搜索+广告+推荐案例》~
专栏作家
King James,公众号:KingJames讲策略,人人都是产品经理专栏作家。算法出身的搜广推策略产品专家。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com