
作者 | 程茜编辑 | 心缘
智东西7月19日报道,今日下午,在字节跳动AI技术菁英论坛上,字节跳动豆包大模型视觉基础研究团队负责人冯佳时主持,多位视觉大模型研究的关键人物集中演讲,详细解读字节跳动在视频生成和3D图像生成模型的一系列创新技术。
作为国内短视频王者,字节跳动是国内最受关注的AI视频生成玩家之一,从去年11月发布高动态视频生成研究成果PixelDance、今年发布AI视频生成模型MagicVideo-V2和开启AI创作工具即梦Dreamina视频生成功能的测试,每次进展都吸引了大量开发者关注。
今天,字节跳动研究科学家周大权回顾了字节跳动过视频生成模型的三年发展历程,以及字节在连续高动态长视频生成技术上的探索。
此外,字节研究科学家Bingyi Kang、张健锋、廖俊豪分别分享了单目深度估计基础模型Depth Aything、多视角条件扩散模型Magic-Boost、拖拽式图像编辑工具InstaDrag的最新成果。
一、视频生成一分为二,先文生图、再图生视频
字节跳动研究科学家周大权的演讲主题是《连续高动态的长视频生成方案探索》,为了让生成视频中主要角色的运动范围扩大,字节跳动将这一过程分为文生图、图生视频两步,使得模型生成所需的GPU资源和训练数据减少。
2022年,字节跳动发布了视频生成模型的第一个版本,在这之后,研究人员开始在移动算法、硬件效率等维度进行模型优化。在运动算法优化方面,研究人员需要创建长视频数据集。

目前,视频生成效果中运动范围都较小,如下图中人物的运动轨迹实际上在整个画面中只占很小的位置。

想实现更加动态的视频效果,需要繁重的GPU资源以及大量训练数据。

研究人员通过保持给定Token一致性,就可以确保生成不同时刻的剪辑是相同Token。
通用视频生成模型的最终目标是希望不投入太多GPU资源以及大量数据,同时生成过程可控。把这些结合起来就是字节跳动研究人员的最终解决方案。
他们将文生视频分为两个过程,从文本到图像的处理过程只需要文本和图像数据,第二步是图像到视频。在文生图的过程中让不同图像持有相同ID,就可以降低训练难度。

周大权称,有时用户只需要输入一句话就可以独立生成六个不同图像,将这些图像组合起来成为一段视频就可以降低学习的复杂性以及模型实现的难度。
在这之中,研究人员修改了图像相似度计算过程中的注意力,它们只需要计算单个图像内的相似度。研究人员现在只将上下文扩展到相邻图像中,利用这种新的自注意力机制,就可以进行文生图像以及图像到视频的组合。
同时,在基于独立文本生成图像时,其还可以保留细节。图像转换为视频时,该模型可以预测这两个图像之间的中间帧,然后生成中间视频,从而生成拥有无限镜头的视频。

二、DepthAything,成高质量2D转3D图像新思路
字节跳动研究科学家Bingyi Kang的演讲主题是《DepthAnything:单目深度估计的基础模型》,该模型可以更有效地从2D图像中识别出深度信息图,让普通手机拍摄的2D影像也能快速转3D。
基于语言和视觉的基础模型可以提供很强的现实泛化能力,其背后的难题就是数据方案和模型方案。DepthAything提出了一种单目深度估计技术,能更有效地从2D图像中识别出深度信息图。
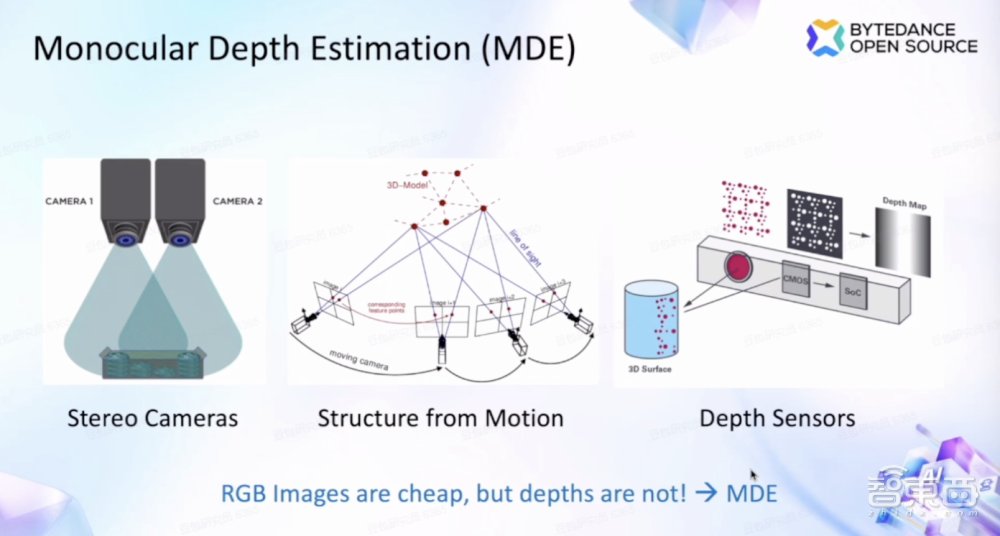
基于此,字节跳动的研究人员进行了数据缩放,Bingyi Kang谈道,首先是汇总所有的数据,研究人员集成了6个公共数据集和大约1500万张图片。随后基于这些数据训练模型。研究人员在标记图像上单独训练教师模型,并通过这个教师网络对所有图像进行适当处理。
为了让数据标记更有效,研究人员采取了两种措施,第一种是将数据增强添加到未标记的图像中,第二种是使用非知识论文损失函数。

此外,真实数据有一定噪声,会出现错误匹配的情况且成本很高。因此,他们首先在纯合成图像上训练一个教师模型,然后使用这个教师模型对所有未标记的图像进行工作室标记,然后只使用真实图像的学生标签来改变学生模型。
DepthAnything技术的应用有望使得短视频平台上的2D影像转化为3D影像,或将应用于XR产业。

三、Magc-Boost:15分钟优化三维图像生成,复杂纹理、几何结构都能重现
字节跳动研究科学家张健锋的演讲主题是《Magic-Boost:通过多视图条件扩散提升3D生成》,可以在15分钟内优化生成结果,从而保留复杂的纹理或者几何结构。
三维技术在电影视觉特效、AR等场景中拥有广泛应用,人们可以自定义自己的角色、视觉效果,城市生成技术可以应用于城市规划、工业设计等。目前,研究人员多利用二维扩散模型生成多视角图像,然后再将这些图像转化为精准3D模型。

张健锋谈道,首先可以给定文本或图像的输入内容,通过多个不同模型生成,然后使用快速重建模型从多个图像中重建相应的城市对象。这一过程通常可以在10秒内完成。
但这一生成的图像与原始输入之间仍会存在明显的性能差距,字节跳动的研究人员提出了多视角条件扩散模型Magc-Boost,可以利用多个图像来优化成本生成结果,这一优化时间大约为15分钟,其目的在于让图像中能尽可能多包含对象的细节信息。
在与其他结果进行比较中,Magc-Boost可以实现快速精化,并保留过程中的内容特性,并能在短时间内快速改进细节。
四、InstaDrag:拖拽一下,1秒搞定照片编辑
字节跳动研究科学家廖俊豪的演讲主题是《InstaDrag:从视频数据中学习快且精准的拖拽式编辑》,InstaDrag可以使得用户进行图像编辑时速度最快提升百倍,在大约1秒内完成高质量拖拽式编辑图像,还能保留无需编辑区域的特征。
目前,一些图像编辑工具中,用户精确控制将其移动到特定位置等基础功能还无法实现。廖俊豪称,因此,一个快速高效的基于拖拽的图像编辑方案十分必要。
在图像编辑工具中,字节跳动的四个目标就是快、未编辑区域不会产生变化、外观不变、 将图片信息移动到目标位置。
相比于此前的方式,InstaDrag的图片编辑可以实现10-100倍的速度提升,同时编辑更准确。同时,自然视频中会包含大量的运动线索,这些视频数据就可以形成配对监督来训练模型。
为了保证未编辑区域不发生变化,研究人员提供了一个遮罩,可以确保遮罩外的每个像素保持不变只拖动遮罩内区域。

在Demo演示中,用户选择遮罩区域并进行相应拖动后,会出现4个结果以便从中选择。
结语:视频、3D生成模型爆发机遇已来
世界模型,被认为是通往AGI的关键路径之一。想要真正理解物理世界,也就意味着需要更多视觉信号,如二维、三维图像、视频等。
近一年来,AI视频、3D生成领域的热度持续攀升,多家AI公司推出了新的视频生成模型,引发了行业内的激烈竞争,从图像生成、图像编辑到更为复杂的长视频、三维信息生成等模型问世,彻底引爆了这条赛道。
在短视频、AI领域等积累颇深的字节跳动,或许会在这条路上带来更多的惊喜。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com