
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
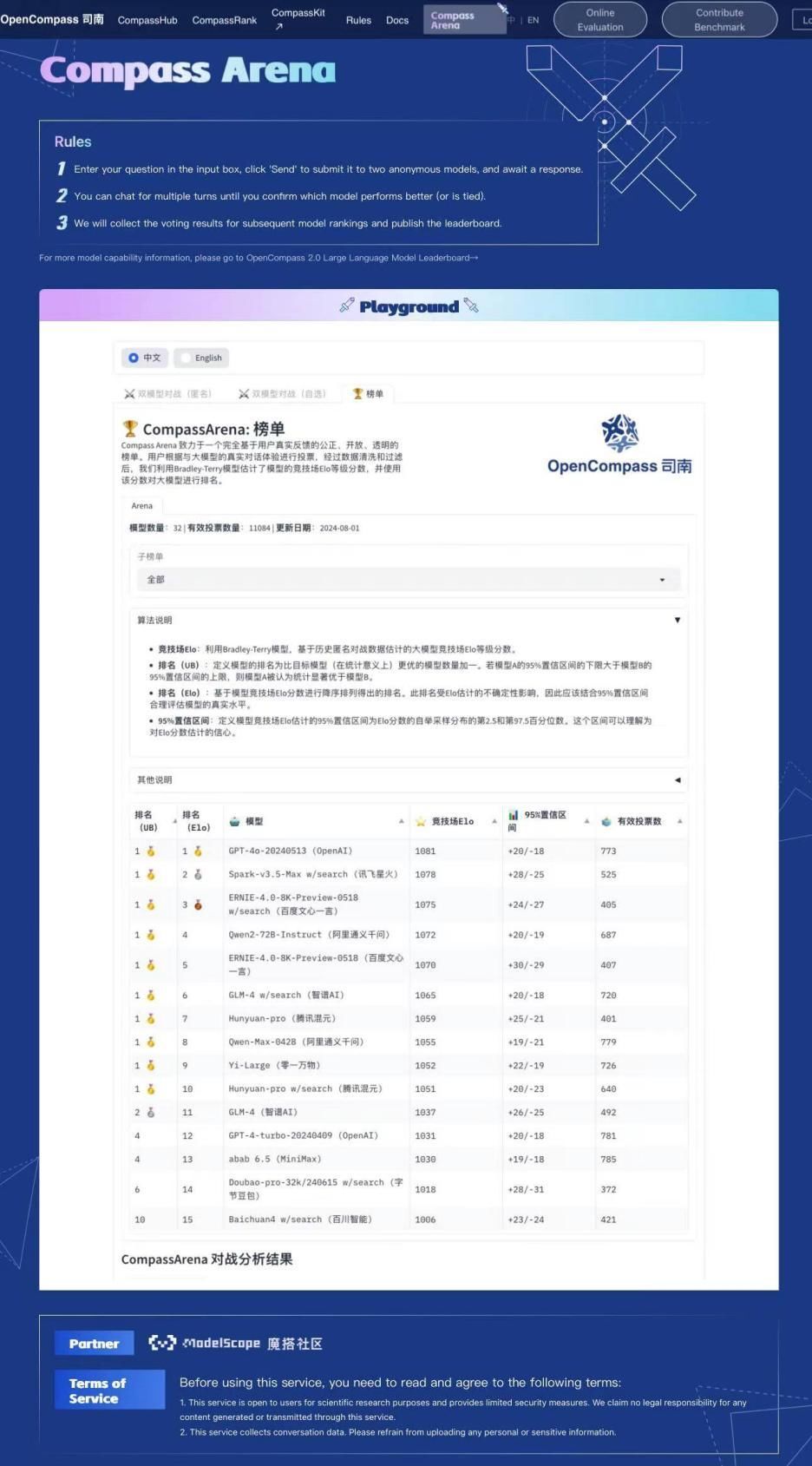
OpenCompass公布大模型投票周榜 讯飞星火蝉联三次三甲
77
0
相关文章
近七日浏览最多
最新文章
标签云
人工智能
天眼查
科大讯飞
南京
自适应巡航
上汽大众
主力资金净流入
板块
洪都航空
周榜
金融界
数字经济
郑州
寒武纪
股份
应收账款
减持
英伟达
价值投资
中国证监会
nlp
毛利率
云南
中信证券
中国石油
大众
牛米
辅助系统
万军伟
联盟
中国青年
奔腾b70
大众朗逸
奔腾
etf
计算机系
大众集团
续航里程
轿跑suv
恒瑞医药
兴业证券
美的集团
证券
短剧
阅文
网文
原创
公子衍
雨欣
抖音
天神
霸榜
洗牌
收视
韩剧
好搭档
张娜拉
私藏浪漫
智能驾驶
李想
何小鹏
吉利
蔚来
共享单车
理想汽车
中国汽车
车叔
新能源车
新能源
中国科技公司
快科技
小鹏汽车
小鹏
小米雷军
特斯拉
mega
高考
大盘
番茄
宫崎骏
数码宝贝
金像奖
哈尔的移动城堡
海豹
app
科技
koc
光点
王牌部队
肖战
刘学义
任嘉伦
鞠婧祎
netflix
蜡笔小新
唐人街探案2
金秀贤