文|常敏潇 袁滢靓
编辑|邓咏仪
若是说成为开源模型天花板,是Llama大模型的运,那“惨遭泄露”,就是Llama要渡的劫。
2023年3月,Llama 2就因提前泄露,Meta不得不以开源的方式发布模型。
如今,历史再次重演。
太平洋时间7月12日,一名Meta员工透露,Meta计划于当地时间2024年7月23日发布迄今为止Llama最大的参数规模版本:Llama 3.1 405B。他透露,405B将会是Llama系列中首个多模态模型。
然而,就在太平洋时间7月22日,预定发布时间的前一日,Llama3.1的模型和基准测试结果就在Reddit等技术社区上泄露,Llama 3.1的磁力链接(用于下载文档的程序)已经在HuggingFace等社区中流传。
从泄露的结果中看,Llama 3.1的性能,足以媲美OpenAI的GPT-4o!
有AI博主盛赞,Llama 3.1的发布,将又是扭转AI界命运的一天:
△来源:X
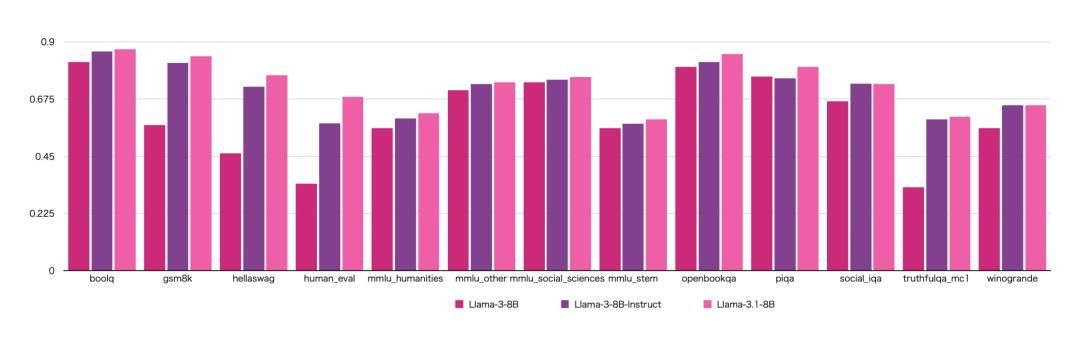
泄露的基准测试结果显示,Llama 3.1共有8B、70B、405B三种规模。参数量最小的70B模型 ,许多方面的性能也与GPT-4o不相上下。
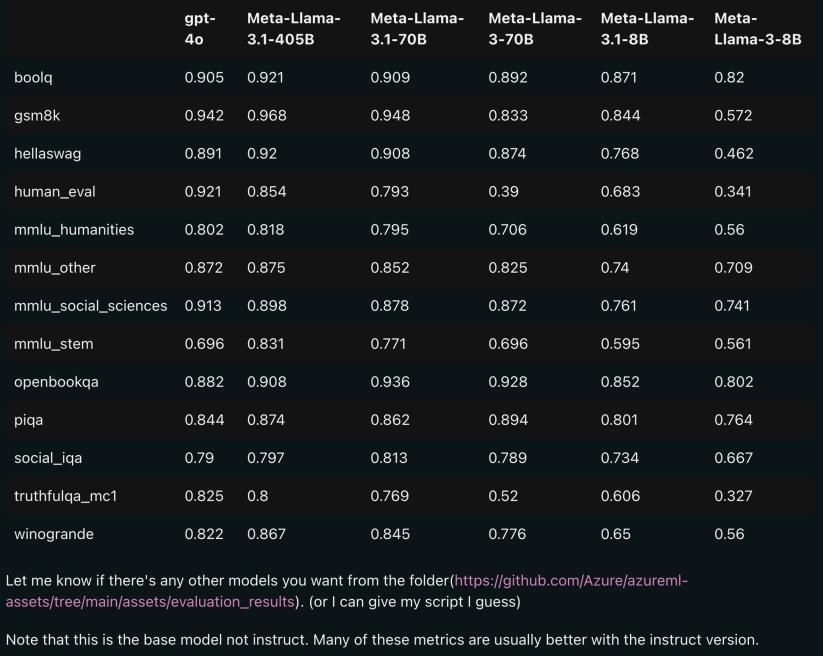
△上图为Llama 3.1 各版本与 OpenAI GPT-4o、Llama 3 8B/70B 的对比,其中,规模居中的70B版本,也在诸多方面超过了 GPT-4o。图源:X用户@mattshumer_
有网友指出,如果依据这个基准,Llama 3.1 405B ≈ GPT-4o,Llama 3.1 70B 则将成为能击败了OpenAI的首个轻量级模型、GPT-4o mini。
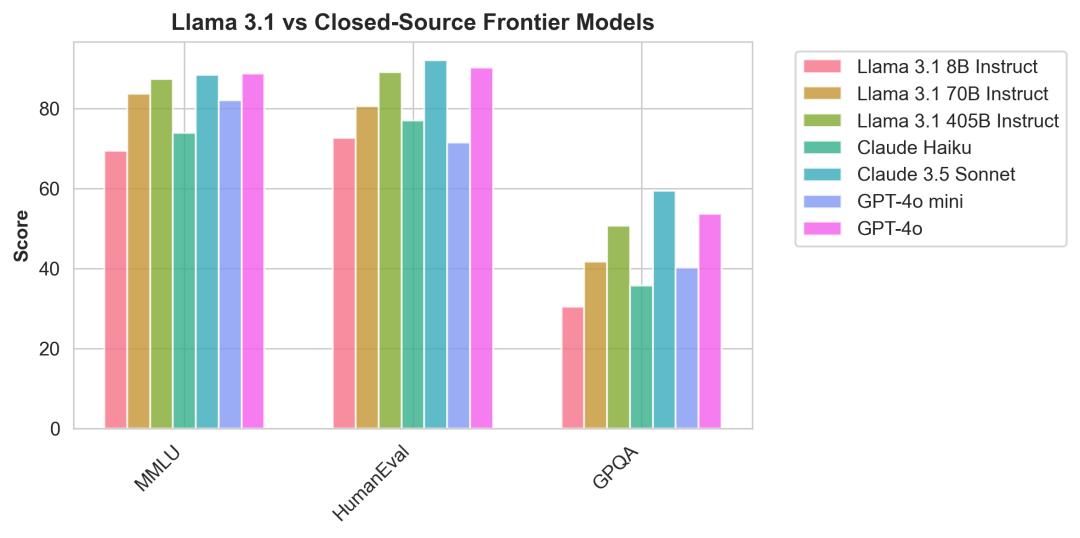
△图源:X用户@corbtt
不过,不少已经下载模型“尝鲜”的网友发现,泄露版的Llama 3.1 405B,所有文件大小竟然约有820GB,所需内存是保留完整精度的Llama 2(约280GB)的近3倍。
这意味着,若非家里有矿,买得起足够多GPU,个人开发者很难用自己的电脑把Llama 3.1跑起来。部分网友猜测,Llama 3.1并非面向个人,而是面向机构和企业。
还未官宣的Llama 3.1也被泼了盆冷水。不少网友倒苦水:Llama 3.1对GPU的要求太高了,不如隔壁OpenAI家的GPT-4o mini物美价廉。
△X上的网友评论。图源:X用户@_Talesh
功能迭代,指标优化,计算资源减少根据泄露的模型信息,Llama 3.1相较于2024年4月19日发布Llama 3,在功能上有了更多的迭代,包括更长的上下文窗口、多语言输入和输出以及开发人员与第三方工具的可能集成。
数据训练:Llama 3.1使用了公开来源的 15T+ tokens进行训练,微调数据包括公开可用的指令调优数据集(与 Llama-3 不同!)以及超过 2500 万个合成生成的示例。
多语言对话:Llama 3.1支持8种语言:英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。虽然很遗憾没有中文,但开发人员可以针对 8 种支持语言以外的语言对 Llama 3.1 模型进行微调。
上下文窗口:每个版本的上下文长度从8k扩展至128k,大致相当于模型一次能够记住、理解和处理9.6万字,几乎是一整本原版《哈利·波特》。
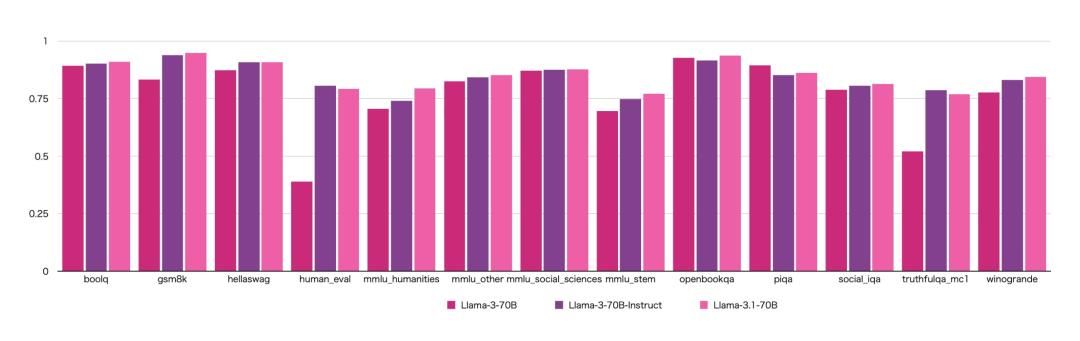
许多网友跃跃欲试,让Llama 3.1与模型“前辈们”一同竞技,发现不仅是指标有了显著提升,计算资源也节省不少。
基于网友的测试,与Llama 3相比,Llama 3.1的能力有显著提升。其中human_eval和truthfulqa_mc1两项能力进步明显,意味着生成编程代码的能力更强、生成问题答案时更具真实性。
同时,Llama 3的instruct(指令)模型相较于base(基座)模型,在提示学习、语境学习、高效参数微调等指标提升明显。
这是合理的,因为base模型通常未经特定任务微调,而instruct模型经过专门训练后,能遵循指令或完成特定任务。通常,instruct模型的指标表现更出色。
这让人更加期待Llama3.1的正式发布。目前泄露的Llama3.1模型测试,结果仅仅针对base模型,而instruct模型表现可能会更佳!
△图源:X用户@thenameless7741
△图源:X用户@thenameless7741
令人惊讶的是,基准测试结果中,Llama 3.1 70B模型打平甚至击败 GPT-4o,Llama 3.1 8B模型则与Llama 3 70B模型性能接近。有网友猜测,这可能采用了模型蒸馏技术,即8B和70B的模型是由405B最大规模的模型简化得出,让大模型变“小”。
模型蒸馏技术可以看作学生向老师学习。大而强的模型(老师模型)是老师,较小且简单的模型(学生模型)是学生。学生模型通过“模仿”老师模型来学习,使输出尽可能接近老师模型的输出,从而学到相似的知识和能力。
经过蒸馏训练后的学生模型,可以减少模型大小和计算资源需求,同时又能保持较高的性能表现和相当的精度。
△图源:Reddit
不是谁都跑得动,但推理价格很划算Llama 3.1到底会不会如愿开源,还是个未知数。但即便开源,想要用得起Llama 3.1,家里仍然得有矿。
想要跑得动Llama 3.1,最基础的入门券,就是足够的GPU。
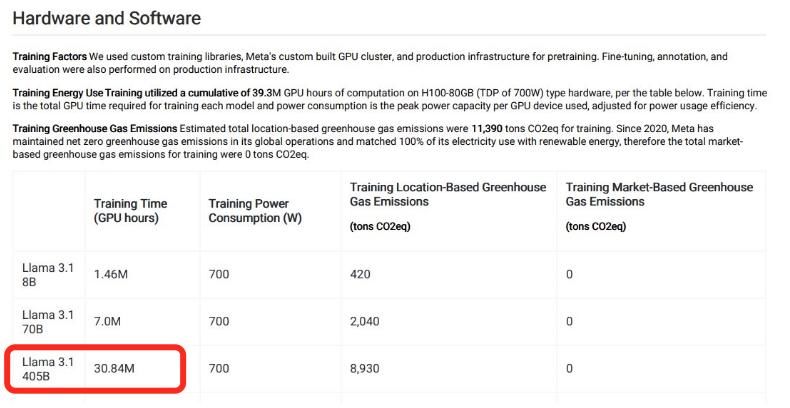
泄露文件显示,Llama 3.1 405B在H100-80GB类型硬件上的训练时间为30.84M GPU小时。这意味着,假设每小时只用一张H100-80GB,运行Llama 3.1 405B就要花30.84M小时——等模型跑起来,要过3500年!
△图源:Reddit
如果想要私有化部署,企业要想在一个月内顺利运行Llama 3.1 405B,就要储备起码43000块H100-80GB。按照4万美金的H100单价算,使用Llama 3.1 405B的算力入场券,就高达17亿美金,折合人民币125亿元。
不过好消息是,Llama 3.1的推理成本,可能会更便宜。
据Artificial Analysis预测,吞吐1百万Tokens所需的成本,Llama 3.1 405B将比质量相似的前沿模型(GPT-4o 和 Claude 3.5 Sonnet)便宜,更具性价比。
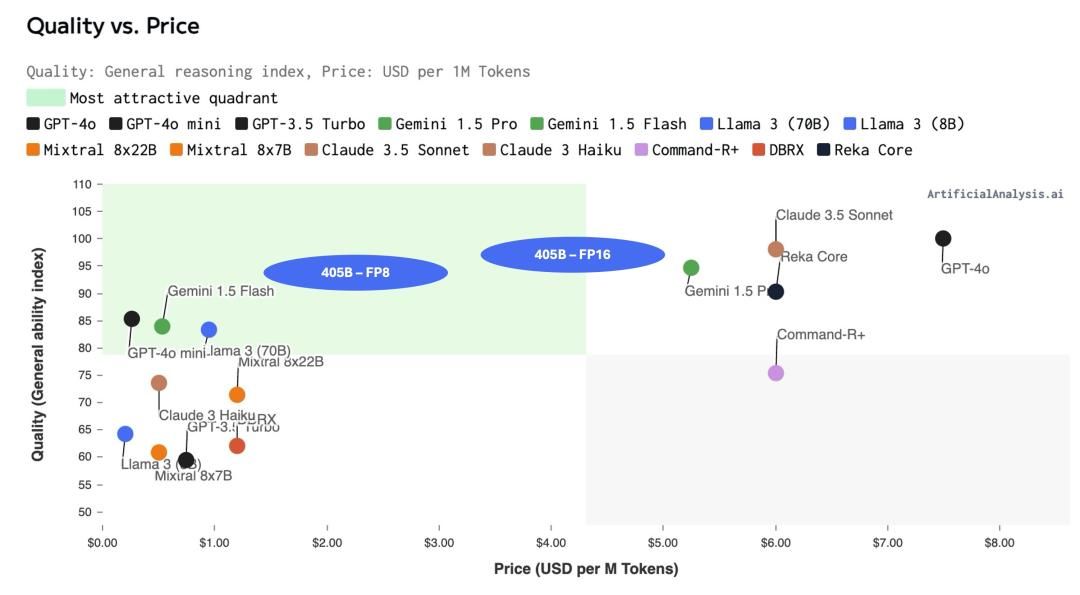
△图源:X用户@ArtificialAnlys
除此之外,有网友通过源文件代码猜测,Llama 3.1 405B可能会成为会员产品,用户使用时需要付费。不过,真实情况如何,还需等待官方发布。
△图源:X用户@testingcatalog
(36氪作者周鑫雨对本文亦有贡献)
欢迎交流
欢迎交流
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com