在 Claude 3 Opus 将 GPT-4 挑落马下的同时,又是一款「最强开源大模型」来了。
当地时间 3 月 27 日,美国初创公司 Databricks 突然公布了旗下开源大语言模型 DBRX,号称是全球迄今为止最强的开源大模型,参数规模达到 1320 亿,表现更是超越 Meta 的 Llama2、「欧洲新秀」Mistral AI 的 Mixtral,以及马斯克旗下 xAI 公司刚刚开源的 Grok-1。
更重要的是,他们只花了 2 个月和 1000 万美元,在性能全面超越 GPT-3.5 的同时,训练时间和成本都只有 GPT-3.5 的一小部分。
不过公允来说,这当然不是一种合理的比较。一方面是 GPT-3.5 发布时的技术和算力成本,都很难和今时今日相提并论;另一方面是,DBRX 采用了与很多大模型不同的:
Mixture of Experts 专家混合架构。
「刷新」开源大模型性能,DBRX 验证了大模型训练的另一条路
Databricks 说 DBRX 大模型是全球最强,并非空穴来风。
首先,DBRX 在语言理解、编程和数学等核心能力的基准测试上,很轻松就击败了 Llama2-7B、Mixtral 以及 Grok-1。包括在开源基准测试 Gauntlet 的 30 多个测试中,DBRX 也优于所有对比模型。
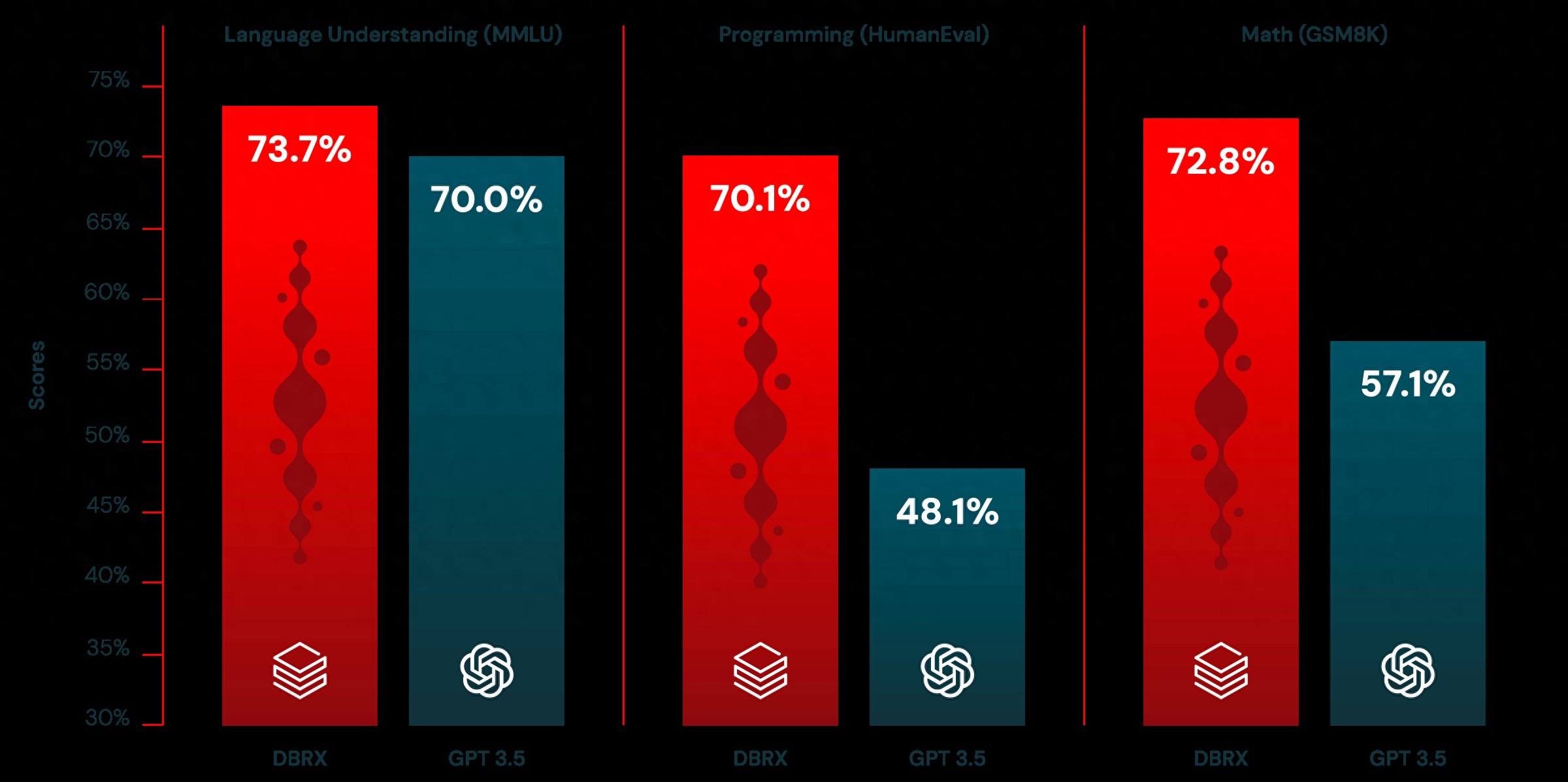
图/ Databricks
另外,不只是开源大模型,DBRX 在大部分基准测试中的表现也超越了 GPT-3.5,甚至在多个测试中非常接近公认第一梯队的 GPT-4。
最后也是关键的,尽管 DBRX 拥有 1320 亿参数,Llama 2 的参数规模是 700 亿,Mixtral 是 450 亿,Grok 则达到了 3140 亿,但在实际运行中,DBRX 平均只激活约 360 亿参数来进行推理。
这也让 DBRX 拥有了更快的生成速度和更低的推理成本,简而言之就是更好的使用体验和性价比。
而做到这一切的基础,在于前文提到的专家混合框架。
众所周知,算力、数据和算法是人工智能的三要素。在算法上,谷歌团队于 2017 年发布的 Transform 架构至今依然是所有大模型的底层架构。DBRX 则在 Transform 架构的基础,采用了一种最早于 2022 年年底提出的专家混合架构,事实上包括前面提到的 Mistral AI 也在去年推出了基于该架构的 Mixtral 8x7B。

提出专家混合架构的论文,图/ arXiv
在该架构下,根据具体询问的内容和问题,模型只会激活不同的「专家」子模块进行推理,在吞吐量一定的情况下,可以更快地完成推理、给出回答。换言之,DBRX 的参数规模将近 Llama-70B 的两倍,性能更强也更聪明,同时实际的推理速度和成本也都来得更好:
让大模型的性能和速度变得「鱼和熊掌,可以兼得」。
再加之训练的最后阶段,Databricks 的开发团队还将重点转向数据,采用「课程学习」的方式提高了 DBRX 的性能。
最终,「我们将开源大模型推向了新的技术水平,」Databricks 首席神经网络架构师兼 DBRX 构建团队负责人 Jonathan Frankle 说。

左一为 Jonathan Frankle,图/ Databricks
值得一提的是,Jonathan Frankle 在接受《连线》杂志采访时还透露,尽管他们相信专家混合框架的潜力,但在 DBRX 真正训练出来并完成基准测试之前,其实也不敢笃定最后的效果,甚至根本没想到 DBRX 还有在代码生成上的优势。
但不论如何,DBRX 都可能改变大模型的迭代和应用方式,更可以确定的是,开源大模型之争,还在继续加剧。
开源大模型:从 Meta 独占鳌头,到百家争鸣
前段时间,央视报道指出国产大模型之路面临的三大挑战,其中之一就是大多数国产模型基于 Meta 的 Llama 大模型,缺乏自主性。
其实不仅在国内,去年 7 月 Llama2 宣布「免费可商用」推出后,一举成为了全球开发者首选的开源大模型。毕竟只要经过简单的微调就能直接应用,何乐而不为。
不过 AI 行业的变化来得又快又凶猛:
先是 Mistral AI 发布 Mistral-7B,宣告全面超越更大参数规模的 Llama2-13B;
不久后,阿里宣布开源 720 亿参数的大语言模型通义千问 Qwen-72B,性能超越标杆 Llama2-70B,号称最强中文开源模型;
稍晚,谷歌也通过发布 Gemma 开始进入开源大模型的竞争,凭借 70 亿参数碾压 Llama2-13B(130 亿参数)。
现在我们又看到了,Databricks 也带着最新发布的 DBRX 加入了这场开源大模型之争。

打造 DBRX 的团队,图/ Databricks
其实如果从业务层面,这几家开源大模型并没有太大的矛盾,比如 Databricks 作为一家面向企业的初创公司,打造 DBRX 的根本目的还是为企业客户定制大模型。按照官方的说法,从发布之日开始,企业客户就能在 Databricks 平台上利用 RAG 系统中的长上下文功能,用自己的私有数据构建一个自定义的 DBRX 模型。
但开源大模型之争的根源在于:不管开发者还是用户,都更倾向于最好的开源项目,群聚效应可能远比闭源大模型来得明显。
换句话说,最好的开源大模型往往会吸引闭源大模型之外的绝大部分厂商、开发者和用户,并基于此推动大模型的快速迭代和生态扩张。如果类比起来,就像是智能手机早期,Android 在一众移动操作系统(iOS 除外)中脱颖而出,并一举成为苹果之外厂商、开发者和用户的共同选择,随后走上了体验改进和生态扩张的快车道。
战争还在继续
显而易见,大模型的战争还在继续,就算是 OpenAI 也不敢一刻放松技术上的领先优势。君不见在最新的 Chatbot Arena 聊天机器人排行榜中,Claude 3 Opus 在经过时间洗礼和群众检验后已经超越了 GPT-4。
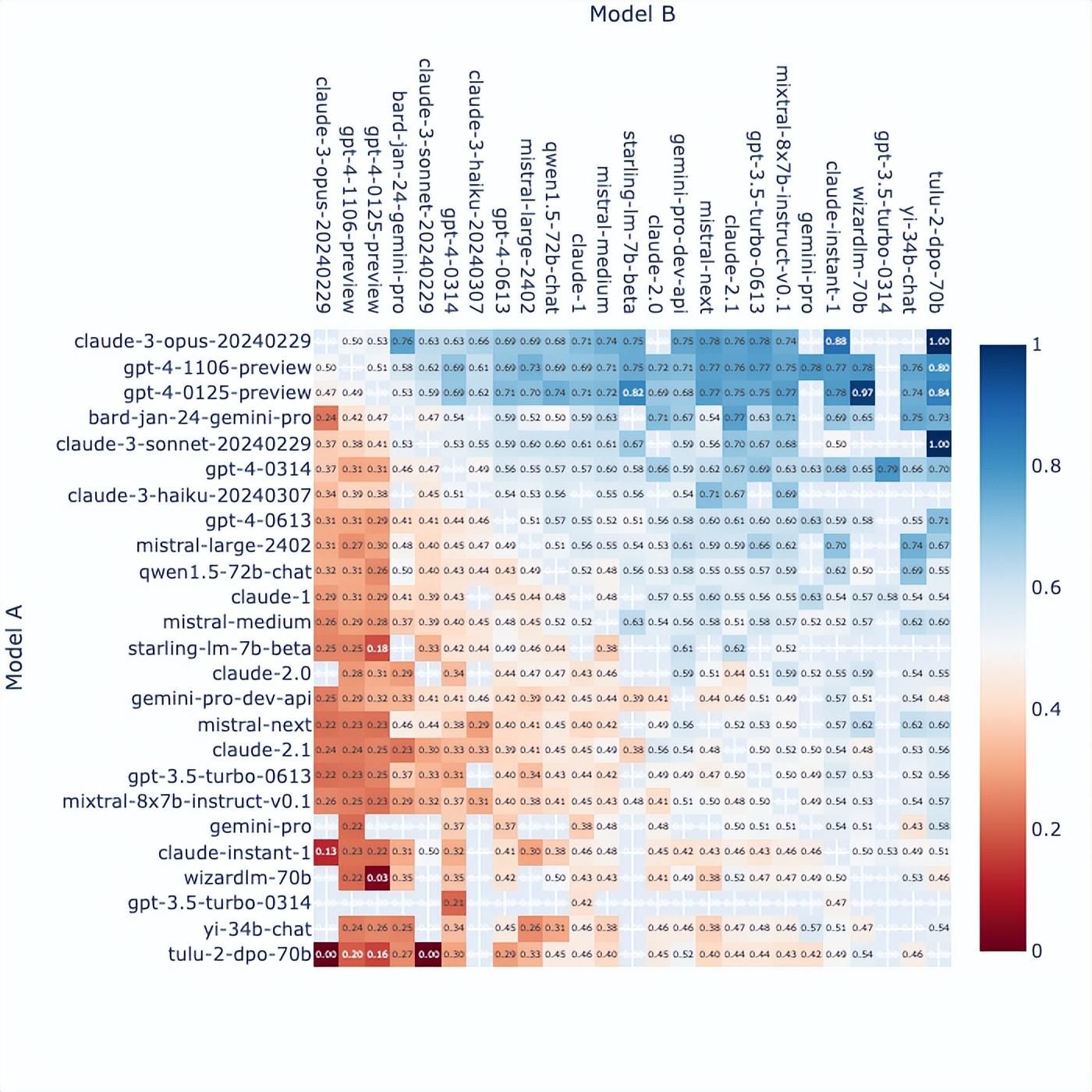
Chatbot Arena 对战图,图/ Hugging Face
开源大模型的战争当然也在继续,不管是谷歌、Meta、阿里,还是 Mistral AI、Databricks 以及更多的开源大模型厂商,都还在继续进行迭代,提高性能、提高效率。毕竟谁也无法笃定在这场快速变化的技术革命中,能不能守住甚至扩大优势。
Meta Llama2 虽然今天被连续吊打,但别忘了,扎克伯格已经预告了正在训练的 Llama3。按照雷科技之前的推算,我们可能在 7 月就能看到一场「复仇战」,届时 DBRX 能不能守擂成功:
我很好奇。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com