“未来,自然语言将成为新的通用编程语言,你只要会说话,就可以成为一名开发者,用自己的创造力改变世界。”
4月16日,百度创始人、董事长兼首席执行官李彦宏在Create 2024百度AI开发者大会上表示。
Create大会是百度自2017年起每年定期召开的开发者大会。会议开始,李彦宏首先晒出了过去一年的成绩单:其中,百度旗下的文心一言用户已超2亿,服务的客户数达到了8.5万,利用千帆平台开发的AI原生应用数超过了19万。

来源:百度
本次发布会的重磅发布,简单而言就是:基础模型全面更新,推出4.0工具版,百度还带来了三大AI开发工具,对应不同的开发场景。
“它们组成了一个工具箱,支持开发者打包带走,随取随用。”李彦宏表示。他表示,自然语言将成为新的通用编程语言,未来,只需要会说话,人人都能成为一名开发者。
回溯文心一言的,百度旗下的“文心一言”基础大模型,在去年就已经经历了多次更新:
- 2023年3月,文心一言3.0版本,当时主要集中在基础模型的能力之上,包括知识增强、检索增强、对话增强等能力;
- 2023年5月,文心大模型发布3.5版本,除了基础模型升级能力之后,还进行了精调技术创新、知识点以及逻辑推理能力增强;
- 2023年10月,文心大模型发布4.0版本,在底层,大模型可以提供超过万卡的算力,而且百度也升级了旗下的开发平台“飞桨”,以及多维数据、多阶段对齐能力。
如今,百度的基础大模型已经有多个版本,包括ERNIE3.5和4.0,和轻量版的ERNIE Speed、Lite、Tiny等尺寸。
相比一年前,新升级的文心大模型4.0,算法训练效率提升到了原来的5.1倍,周均训练有效率达到98.8%,推理性能提升了105倍,推理的成本降到了原来的1%。
其中,推理成本的大幅下降,对于大模型降低应用门槛意义最大。也就是说,客户原来如果一天调用模型1万次,现在同样的成本可以调用100万次。

来源:百度
三款新AI开发工具:不懂代码,也能开发智能体和AI应用“4.0工具版”到底是什么?
过去一年,尽管大模型的能力水平更新日新月异,技术圈时时惊呼“史诗级更新”,但大模型离普通用户的生活依然很远。这次新发布的三款工具,可以看作是文心一言在基础模型之上更进一步:为开发者甚至不懂技术的用户,提供的更多低代码/无代码开发工具。
这次的三款工具分别:智能体开发工具AgentBuilder,AI原生应用开发工具AppBuilder,以及各种尺寸的模型定制工具ModelBuilder。
前两个工具分别对应了不同的开发需求:复杂任务执行、App快速开发;ModelBuilder则是面向专业开发者,需要定制任意尺寸模型的需求。
李彦宏在会场举了大量例子,来说明三款工具的应用场景。
例如:AgentBuilder就是最贴近普通人使用方式的工具。智能体可以批量生成,应用在各种各样的使用场景。
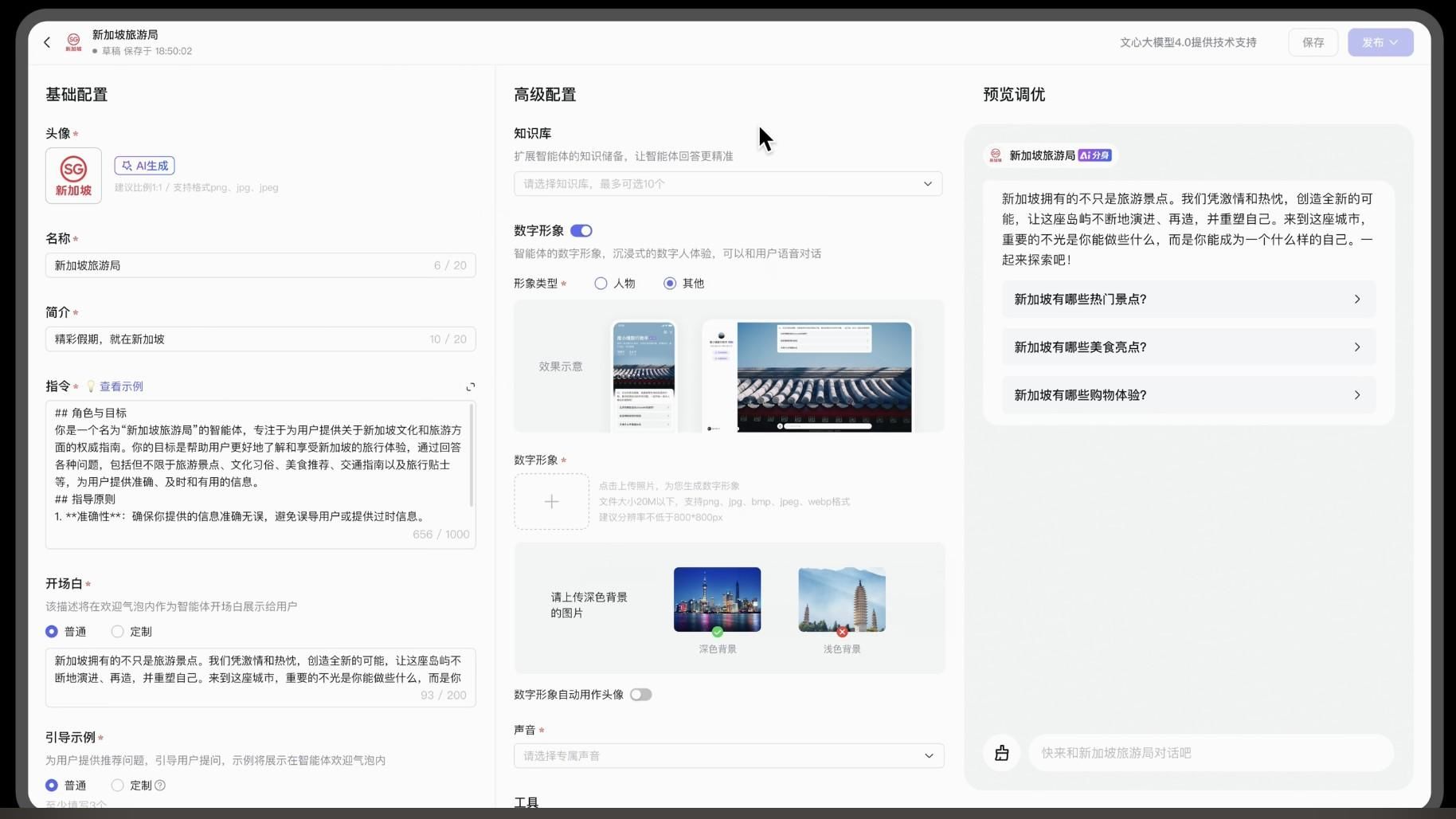
新加坡旅游局Agent开发界面 来源:百度
李彦宏以“新加坡旅游局”举例,如果需要根据为旅游局开发可以规划旅游路线、解答旅游问题、预订门票的“智能体”。只需要用零代码模式,用自然语言和AgentBuilder进行交互,就能够让平台开发一个基础版本。
如果需要更专业的版本,用户可以把新加坡百科词条和官网链接都添加到知识库里,就能实现每天实时更新。另外,百度也在工具中内置了超过25种预置工具,覆盖电商、互娱、办公、专业服务等场景。
文心智能体平台已有许多用户开发的Agent 来源:百度
第二个开发工具AppBuilder,则提前封装和预置了开发AI原生应用所需的各种组件和框架。
最快只需三步,开发者就可以用自然语言开发出一个AI原生应用,能够便捷地发布、集成到各种各样的业务环境中。
百度以“游乐场排队规划助手”的开发实例为例,开发者需要做出一个应用,需要在不同排队时间的项目中规划最佳路线,让游玩的刺激指数最高。
开发者只需做以下几步,不需要输入一行代码就能生成一个应用:
- 在角色指令中描述具体要求,包括调用代码解释器、算出在固定时间内的最佳组合、输出结果等;
- 到工具组件中,把代码解释器添加进来,帮助运算;
- 开始实际应用,用户输入问题“我有3个半小时时间,怎么玩最刺激?”,代码解释器就会将问题翻译成代码,并且对已知的数据(项目排队时间、刺激程度)进行排列分析,最后输出路线。
简单来说,比起去年通过大模型简单生成一些图片、表格,如今有了AI开发工具,用户就能自由选择调用其他的模型,像搭建乐高一样,完成更复杂的任务。
第三款模型定制工具ModelBuilder,主要满足的是专业开发者的需求。许多场景并不需要很大规模的模型,很多时候,小模型通过精调就能实现更好的效果。
作文批改助手模型 来源:百度
百度以作文批改场景为例,首先,作文批改有明确的评分标准,并且不同年级对作文的要求和打分标准,也是不同的。这就需要模型精调,让大模型输出的结果,更符合特定的要求。
因此,通过ModelBuilder,开发者就能先根据自己已经有的作文数据,在平台上完成数据清洗、标注、增强动作,再经过基础模型上的精调,最后部署在平台上,一个专属于作文批改场景的模型就诞生了。
事实上,经过一年发展,百度如今的开发者生态已经颇具规模,截至2024年3月,千帆大模型平台已累计服务用户数超过8万,累计精调1.3万个模型,开发应用数超过16万。
而推出如今的AI开发工具,也是为了“大模型本身并不直接创造价值,基于大模型开发出来的AI应用,才能满足真实的市场需求。”李彦宏说。
开源模型会越来越落后?除了发布新的开发工具外,当前百度大模型落地的思路已经十分清晰:借助大模型,和百度已有产品线紧密结合。
比如,百度旗下的智能音箱“小度”,就借助大模型变得“更聪明”了。
现在,包括OpenAI在内的头部大模型厂商,在提升大模型能力时,MoE(混合专家模型)已经是较为确定的技术方向,这可以简单理解为在训练和推理时,将不同大小的模型相结合,从而实现更高效的运算。
本次发布会上,百度也发布了全新的AI原生操作系统DuerOS X,将MoE模型应用在了“小度”之上。
现在,向小度’提出包括询问新闻、天气、穿衣推荐、路线推荐等问题,每个问题都会分配给不同模型来执行:比如,调用应用的API接口时,会用ERNIE Functions模型;而询问天气,以及需要当天穿衣建议时,小度就会根据天气查询的结果,调用基于ERNIE Lite打造的精调模型,给用户穿衣建议。
小度的更新逻辑在于,基于已有的文心的模型“裁剪”出适合各种场景的更小尺寸模型,通过精调和post pretrain后,能够更显著降低AI应用的成本。“相比全部使用文心大模型的旗舰版,如今小度的响应速度提升2倍,成本下降了99%。”李彦宏表示。
“大家以前用开源觉得开源便宜,其实在大模型场景下,开源是最贵的。所以,开源模型会越来越落后。”他进一步解释。
这个论断看似激进,但基于一个重要的讨论背景:开源还是闭源,哪个应用成本更高。
开源是互联网的根基,无论是从浏览器的出现,到如今的大模型,都离不开开源的贡献。比如,大模型的核心技术Transformer架构,就是谷歌的开源工作。
到了2023年,Meta旗下的Llama 2开源,免费可商用,这瞬间让大模型领域的格局改变——后来者可以直接基于开源的Llama 2模型基础上做微调,进而开始商业化。
开源能够借助开发者的力量,让技术获得突破,但要降低应用门槛,最终还是要走到用户端:产品落地应用,反哺到开发者生态,才会不断提升已有模型的能力。
正因如此,如今OpenAI等头部模型厂商的最新模型,都毫无疑问走闭源战略,并且大力做商业化。李彦宏的观点代表着,大模型领域经历过去一年紧张的你追我赶之后,如今进入新阶段:商业化效率,将会成为接下来模型能力提升的重要变数。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com