毫无疑问如今是AI的年代,各大厂商都希望自家的产品能够搭乘上AI的顺风车,从而获得行业以及用户的青睐,更重要的是借助AI这股风,自家的产品也能获得更高的溢价,从而带动营收的增加。就在去年下半年,英特尔推出了Meteor Lake处理器,同时与合作伙伴一起推出了AI PC的概念,希望让Meteor Lake处理器能够扛起AI PC的大旗,不过现在看起来Meteor Lake处理器的AI性能还是有所欠缺,并不能满足微软Copilot +PC的算力需求。

到了2024年,英特尔再一次将移动处理器进行彻底的改造,推出了Lunar Lake处理器,让E核有着脱胎换骨般的改变,而且也砍掉了陪伴多年的超线程技术,更为重要的是这一次英特尔NPU的AI性能提升极其明显,面对微软Copilot +PC也丝毫不怵。现在我们就为大家带来Lunar Lake处理器的架构讲解。
CPU:E核脱胎换骨,告别超线程
作为Lunar Lake架构的核心,处理器的CPU部分可以说有着天翻地覆的变化,首先就是取消了超线程技术,让CPU最高变成了8核8线程,其中四颗为P核,另外四颗为E核,伴随着超线程的消失,仅在Meteor Lake上使用的LPE核也随之不见。英特尔官方则称尽管去掉了超线程技术,但是CPU的性能却没有因此而降低,反而更加出色,其中的最重要的原因就是脱胎换骨的E核。

英特尔在12代酷睿处理器上采用了P核以及E核的混合架构设计,其中P核负责高性能计算,E核则负责高效率的运算。P核与E核也是井水不犯河水,而到了Lunar Lake处理器上,E核的性能得到巨大的提升,例如L2缓存的容量达到了4MB,AI以及矢量计算性能达到了上代的2倍。
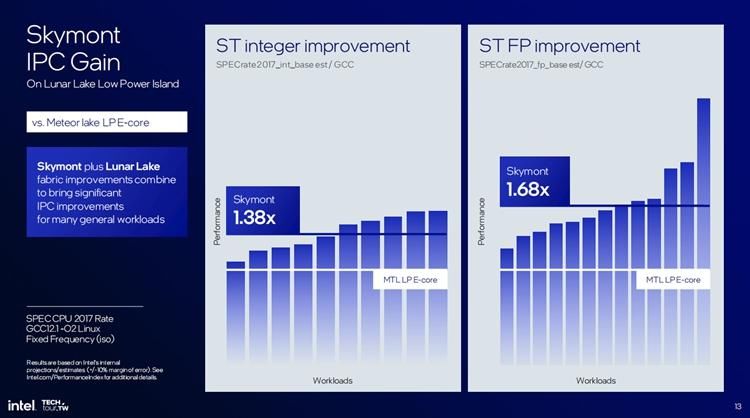
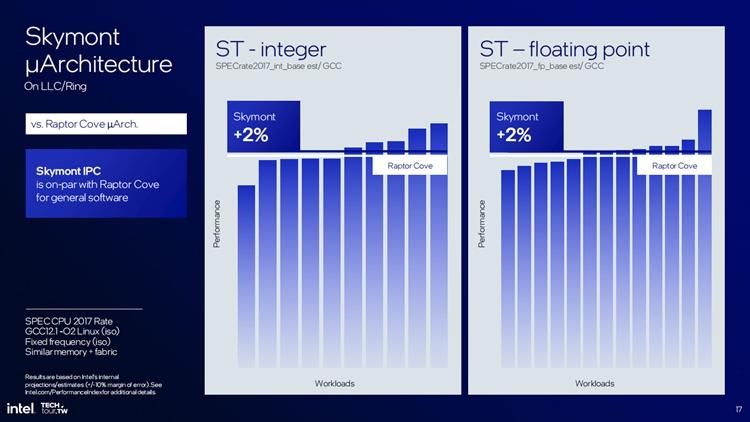
与上代相比,Skymont的IPC整数性能提升了38%,而浮点性能则提升了68%能耗方面,和 Meteor Lake的LP E核相比,在保持继续相同性能的前提下功耗仅为后者的三分之一。事实上英特尔将Skymont按照Raptor Lake处理器的P核性能去设计,最终目标也达到了英特尔的预期。无论是整数性能还是浮点性能,Skymont都比上代的P核提升2%左右的性能。
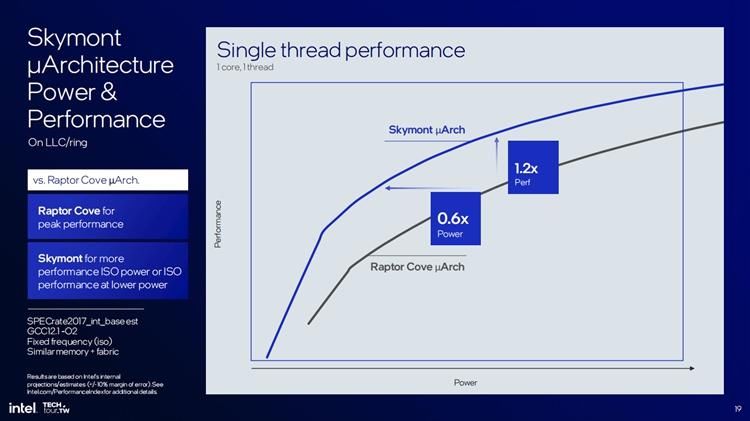

可以说作为E核的Skymont已经和上代P核的性能不相上下,因此英特尔也就没有必要让重型繁琐的任务已经交给P核去运行,英特尔还表示,如果E核能够胜任任务的处理器,那么仅需开启E核就已经足够,这样关闭P核还可以省点电,提升笔记本的续航,毕竟Lunar Lake处理器的用户主要就是超极本。
看完了E核接下来就是P核了,与E核天翻地覆的进步相比,P核最大的改变就是取消了多线程技术,这样技术已经跟了英特尔20多年的时间,而随着E核性能的提升,实际上不开启多线程都可以满足日常办公以及视频剪辑等应用的算力需求。
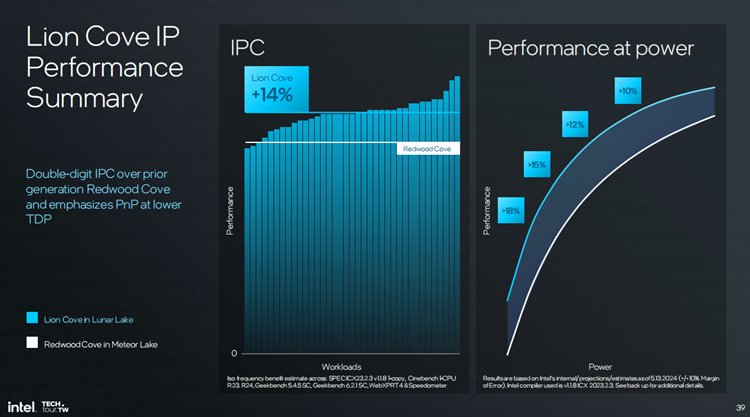
英特尔也举例了在开启与关闭双线程之后处理器的功耗、性能,能效比究竟有多少变化。与上代P核相比,这代P核的能效比提升了15%,单位面积性能达到了10%,英特尔称最后能够让单位面积的能效比提升30%,而IPC则提升了14%,这个程度还是相当恐怖的。
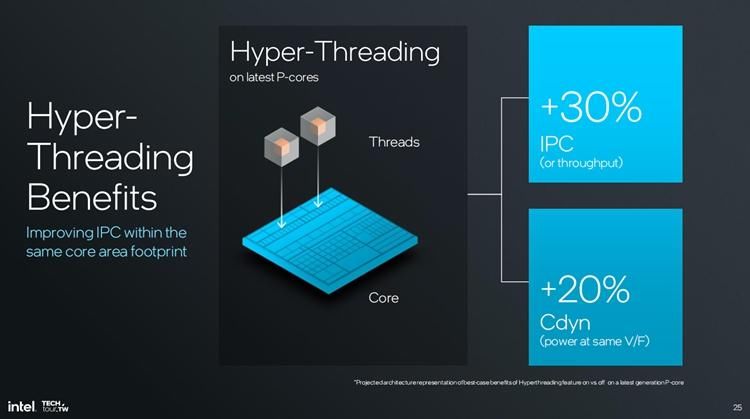
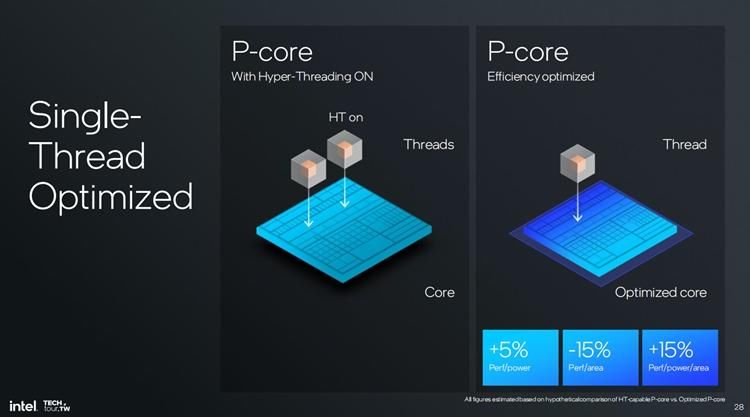
假如打开了超线程,英特尔表示与超线程相比,能效比提升5%,单位面积的性能降低了15%,而单位面积的能效比性能则最终提升了15%,此外英特尔还表示这是在理想条件下进行测试,实际测试的时候还要考虑软件等的优化,因此直接将性能加在E核要远比开启超线程代的能效比提升来的大。

英特尔也利用AI来精准地控制CPU的频率,最小步进为16.67MHz,根据实际的平台温度、环境,设置适当的时间阈值,进而确保CPU频率处于最高效的水平,也让CPU的温度曲线时刻处于理想水平,降低了轻薄版的散热压力。

具体到实际性能上,与上代的P核相比,Lion Cove的IPC提升了18%,而能效比则提升了14%。此外内存对于AI、图形都是至关重要的,所以英特尔这一次把内存集成到了SoC上,通过缩短内存的走线将内存的物理功耗降低高达40%。还可以节省主板面积,最多可以节省250平方毫米,使得主板的价格可以往下降。
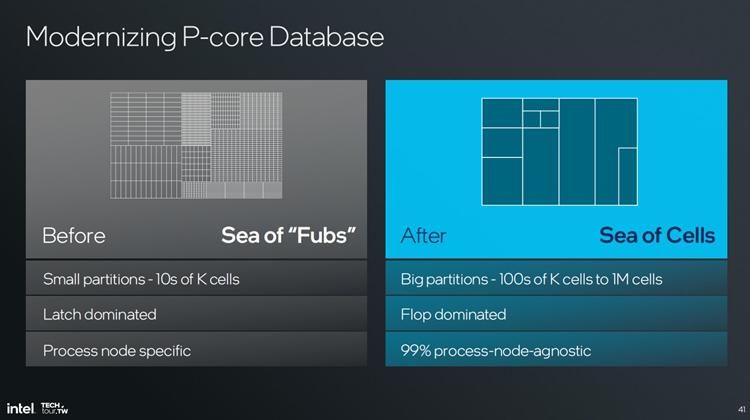
实际上这还不是全部,英特尔还表示随着Lunar Lake的推出,未来英特尔在设计CPU的时候将会采用全新的流程、工具和方法。过去英特尔将CPU分为几百上千个模块,每个模块里面有几万个单元,十分地零散,而到了Lunar Lake时代,英特尔则采用了模块化的设计每个大模块里面包含数十万甚至是上百万的单元.
这种设计可以让处理器的边界大幅减少,从而让芯片的利用率大幅提升,迭代升级也更加方便。英特尔面向高性能计算打造的Arrow Lake与高能效打造的Lunar Lake都采用的全新芯片设计工具,英特尔设计部分也可以很快地进行转换。此外全新的CPU设计思路也对制程的变动不那么敏感,这也对英特尔处理器采用不同制程架构打下了基础。
GPU:采用新架构,AI生图更快

CPU主要还是负责通用计算,而想要让AI发挥更大的作用,GPU的AI性能显然必不可少。而在Lunar Lake架构上,英特尔也首次采用了Xe2 GPU架构,比桌面显卡更早。在Lunar Lake处理器中,每个Xe Core都有八个矢量引擎,每个引擎都有2048比特的宽度,而每颗核心又有192KB的L1缓存,还支持SIMD16指令,从而在游戏以及AI上表现得更加出色。目前随着AI应用的普及和流行,GPU的矩阵计算将会变得十分地重要,而XMX就是提升矩阵计算效率的有效之举。XMX的引入大大加强了矩阵运算的性能。

除此之外Xe2内部也加入了Excute Indirect的支持,传统的图形渲染中,GPU需要得到CPU的指令才可以执行3D任务的渲染,而有了Excute Indirect,无需CPU,GPU自己就可以完成绘图等指令,并且GPU还是并行计算,大大提升了计算的效率,而且也可以降低CPU的使用率,从而降低功耗。上述这些技术让Xe2的顶点以及渲染性能提升了3倍。同时得益于优化后的光追处理单元,Xe2的光追性能也有2倍的提升。
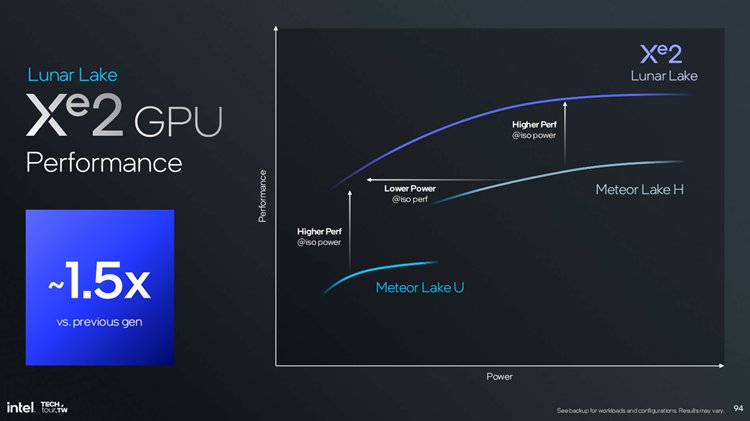
与Meteor Lake所采用的Xe架构相比,Xe2架构的能效比提升了50%,这样可以让厂商有了更多的选择,例如只要15W的功耗就可以实现与25W Xe架构GPU一样的图形性能,这对于轻薄笔记本来说十分地实用。在AI性能上,得益于XMX的加持,这颗GPU可以实现67TOPS的INT8算力,再加上NPU和少部分CPU AI算力,从而让Lunar Lake处理器的AI算力突破了100TOPS。使用Stable Diffusion进行演示,Lunar Lake 的图用了6.3s,而Meteor Lake花了13秒以上,作图时间快了1倍。


此外Lunar Lake也支持DP1.5,VCC也就是H.266视频解码,VCC拥有比AV1更加高效的编码效率,同等画质下体积大约减少了10%,可以让用户使用更小的带宽观看超高清的视频。不过这一次Lunar Lake技术讲解会并没有透露实际的游戏性能提升,大家需要等到Intel未来的发布会上才能知晓。
NPU:不再鸡肋,满足微软需求
这几年AI PC越来越热门,包括ChatGPT的文生文、Stable Diffusion的文生图以及Sora的文生视频对于AI算力要求越来越高,而过去这些任务主要是由CPU以及GPU负责,而随着NPU的加入,这几年越来越多的AI计算开始由CPU转移到NPU之中,英特尔预计明年有30%的AI任务由NPU来承担,因此NPU的算力变得愈发重要。

Lunar Lake一共提供了120TOPS左右的AI算力,GPU贡献了67TOPS,而贡献第二多的便是NPU,上一代Meteor Lake处理器的NPU算力大约为10TOPS上下,显然还不能帮CPU承担一些复杂的任务,而到了Lunar Lake架构中,英特尔NPU已经进化到第四代,能够带来48TOPS的AI算力,并且效率大幅提升,可以说NPU兼顾了效率和算力,未来将会承担更多的AI应用负载。

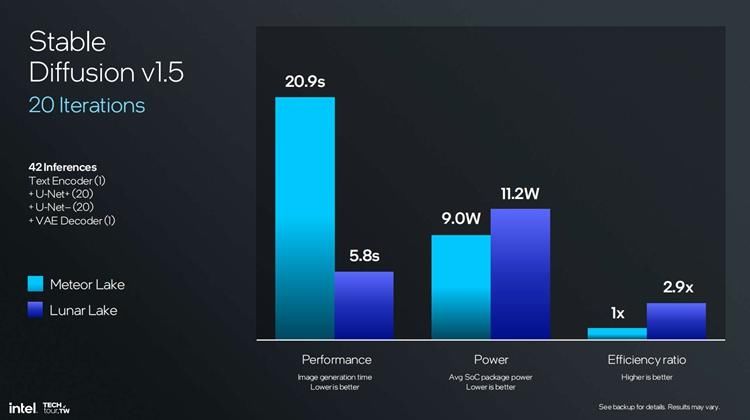
大家平时都在说TOPS,那么什么是TOPS,AI最重要的计算就是矩阵计算,而OP就是每秒能够完成多少次计算TOPS就是每秒完成多少万亿次矩阵计算。Lunar Lake所采用的第四代NPU拥有6个神经运算引擎,每个引擎有4096个运算单元,而上一代则是2个神经运算引擎,纸面算力就有3倍的提升,实际上第四代NPU的运算效率更高,例如英特尔增加了NPU与CPU之间的带宽数据传输速度,而且也增加了NPU的算法,包括INT8以及FP16都可以在NPU上进行计算,因此算力最终达到了前代的4倍。而在Stable Diffusion中,NPU 3的绘图速度为20.9秒,而NPU 4则是5.8秒,速度提升了3倍左右。

从Lunar Lake架构开始,你可以选择让NPU来负责第一步的文本转换,随后NPU继续负责文字解码以及全卷积神经网络扩展,只有最后一步图形输出才是GPU来负责。这样可以让NPU肩负起AI计算与推理中的重担。
ITD:让AI来协助资源分配
英特尔硬件线程调度器是英特尔在12代酷睿处理器中引入了全新单元,它可以实时监控和分析工作负载,能够把正确的进程放到正确的核心上运行,保证最佳的能效。过去硬件线程调度器在处理任务中,优先将任务放到P核,如果P核算力完全能够应付甚至还有多余的算力,那么将会把进程扔到E核中。
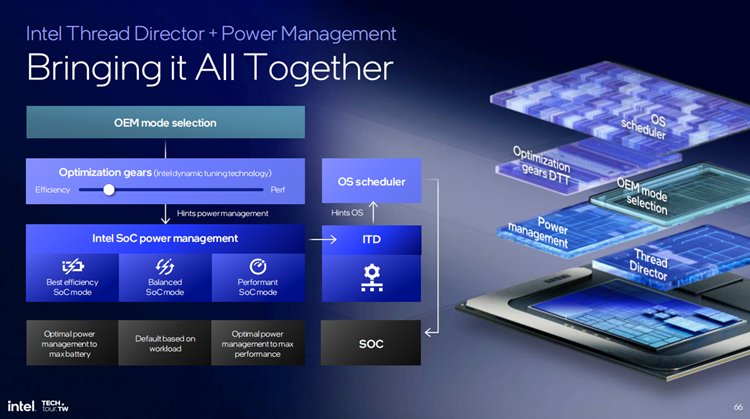
至于Meteor Lake,则首先考虑LPE核,LPE核性能不够才逐级提升,而到了Lunar Lake架构中,它只有两层,先放E核,如果说超出需求就往P核上移。Lunar Lake的E核已经是相当于Meteor Lake的大核,所以英特尔希望Lunar Lake的E核,可以覆盖日常常见的工作负载,只有在重载的情况下才需要往P核上移。这样子可以确保CPU的功耗降到极低的水平。
目前NPU的AI算力越来越大,因此英特尔也将AI引入到线程调度中来,利用于AI机器学习的预测来分配任务,而SoC的电源管理引擎会基于AI的机器学习来判断工作负载到底是属于哪一种,从而让进程能够更加高效地调度。英特尔还表示Lunar Lake与微软Win11作了进一步的融合,还可以让OEM去选择不同的模式,更加地灵活
外部连接:囊括Wi-Fi 7、Bluetooth 5.4与Thunderbolt 4
对于AI PC来说,强大的算力需要强有力的外部连接才能发挥最大的作用,而Lunar Lake则是英特尔首个集成Wi-Fi 7、Bluetooth 5.4以及Thunderbolt 4的处理器架构,同时借助AI的一些新技术来让连接更加高质量。
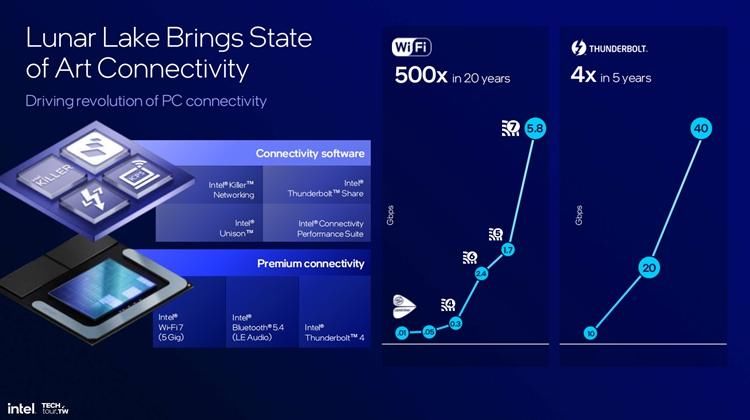
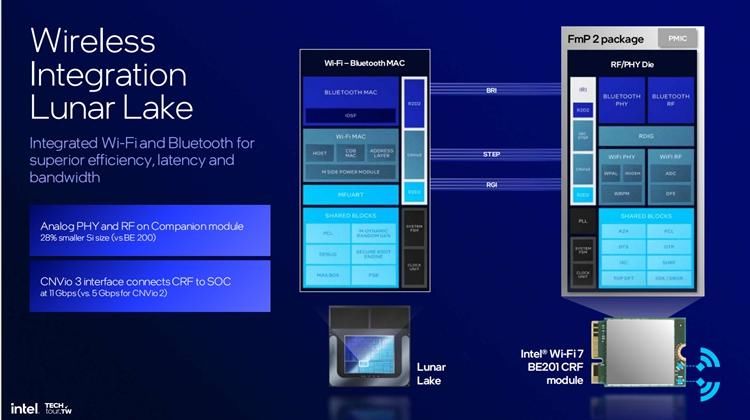
Lunar Lake处理器支持最多3个Thunderbolt端口,还将支持Thunderbolt share,将两个PC连接,实现60帧的屏幕分享,以及超高的数据传输,从而提高工作效率。而Lunar Lake处理器集成了最新的BE201,面积减少了28%,同时可以更快地与SOC相互连接。英特尔希望未来通过AI和Connectivity的结合,让PC更具感知化、智能化。
XPU战略深入其中
去年Meteor Lake可以说是英特尔过去10年来最大的架构改革,英特尔也借助Meteor Lake处理器敲开了AI PC的大门,然而英特尔没想到AI的发展超乎了所有人的想象,促使英特尔对旗下的处理器进行更加激进的设计,从而带来了Lunar Lake架构。

在Lunar Lake上,我们看到了英特尔对于AI运算有着自己的理解,借助更加强大的NPU,取代CPU在AI任务中的角色,另外大幅提升E核的性能,取消经典的超线程设计,从而让CPU的功耗更低,让处理器满足未来的计算需求。而强劲的核显则加速了AI任务的处理速度,即使没有独立显卡也能获得相当不错的作图性能。
最为重要的是,英特尔引入了新的芯片设计方式,这种方式证明了同一个架构,只要利用现代的设计方式,就可以利用不同的制程去做同一个微架构的产品。这给了英特尔更多的制程选择余地。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com