










友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
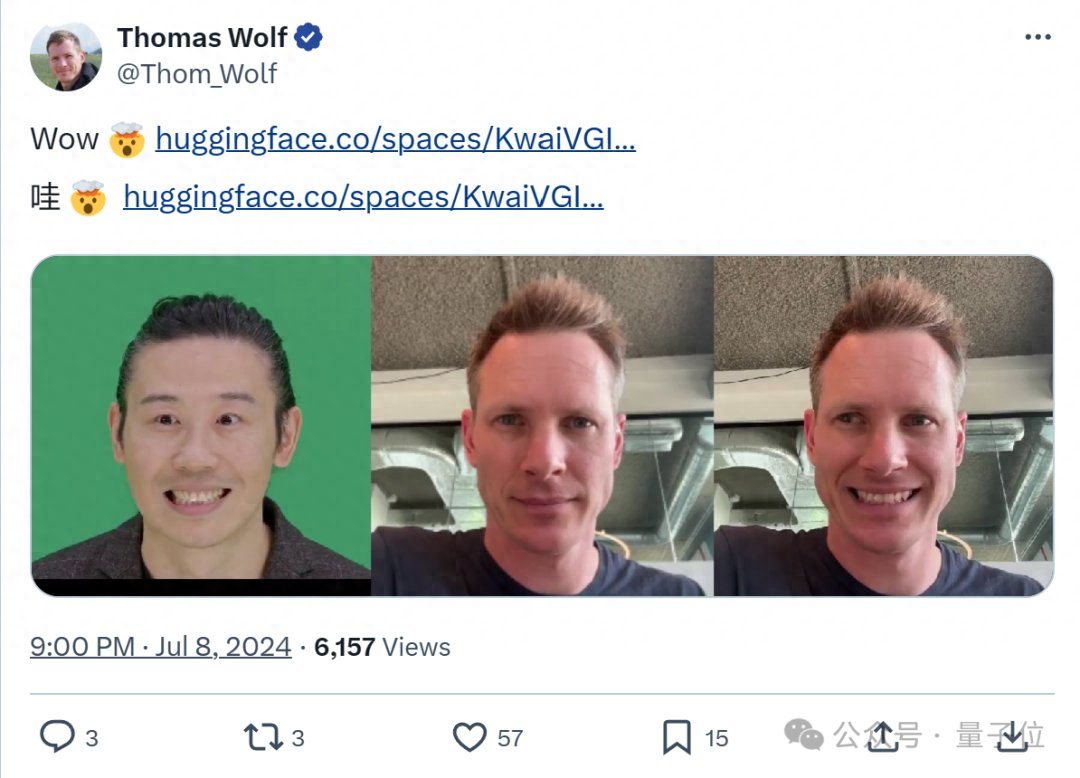
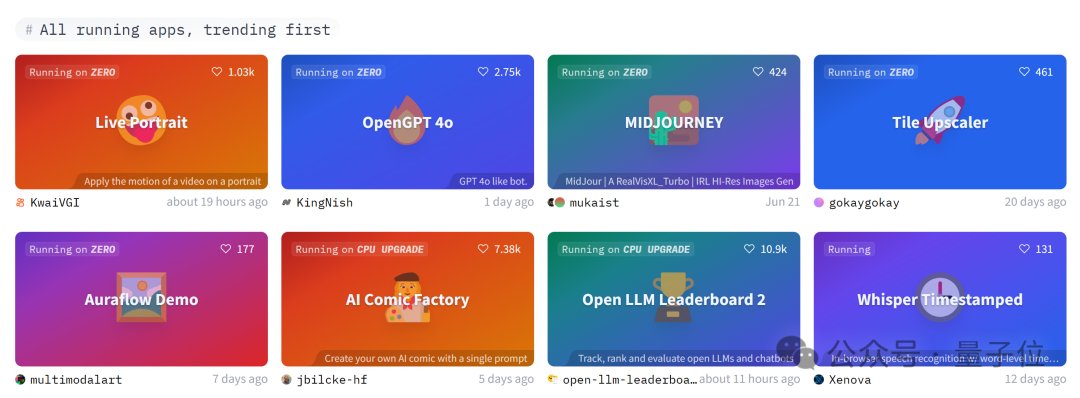
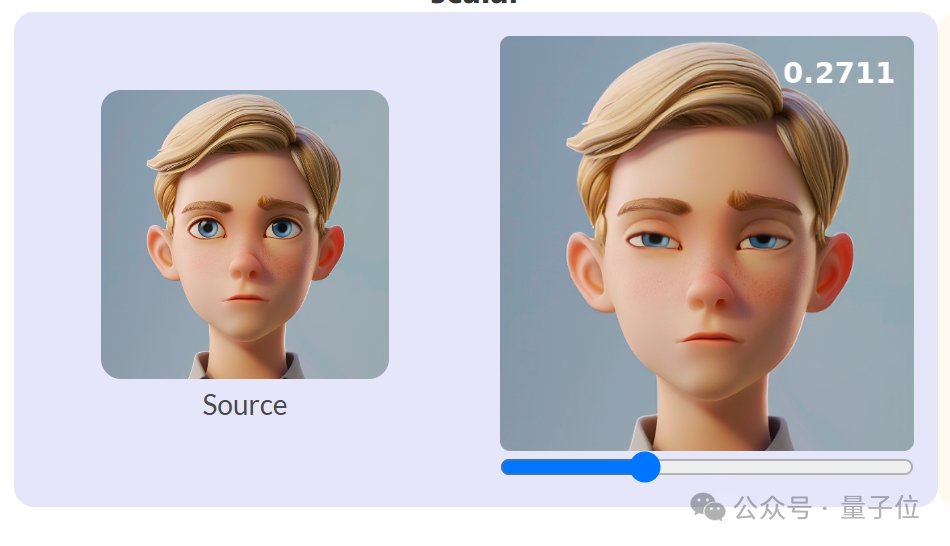
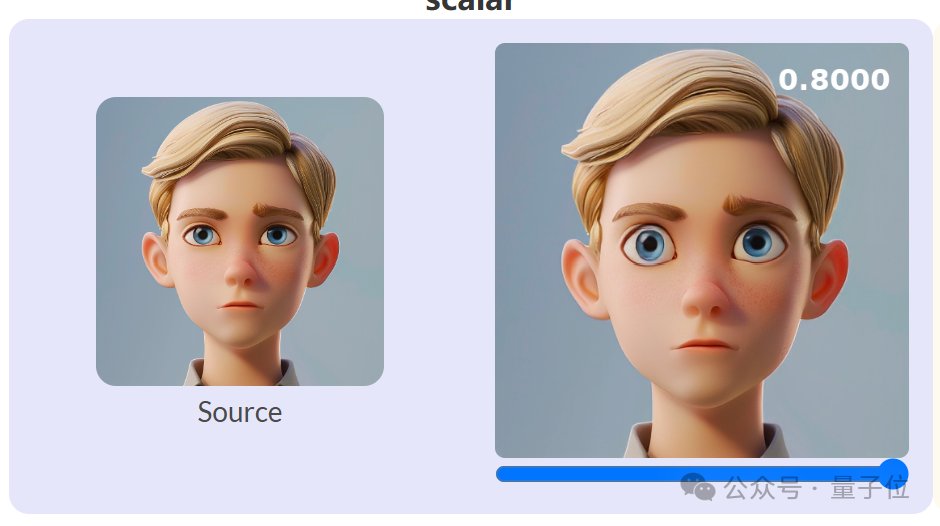
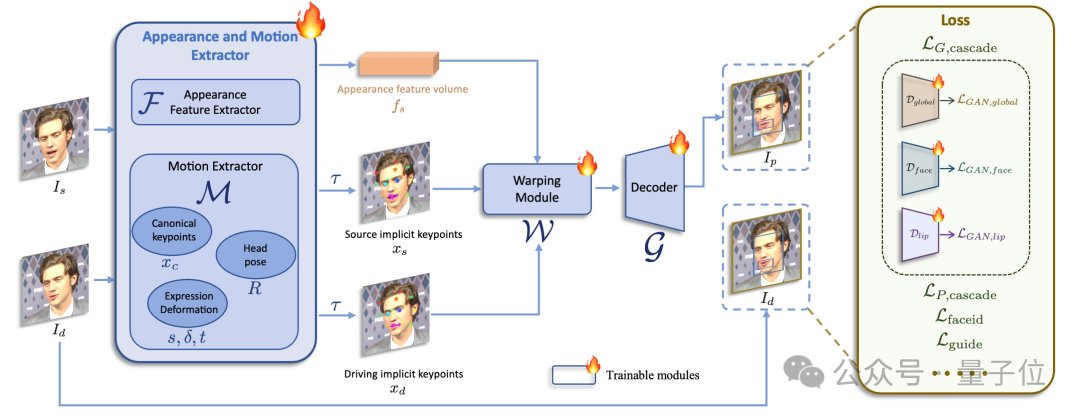
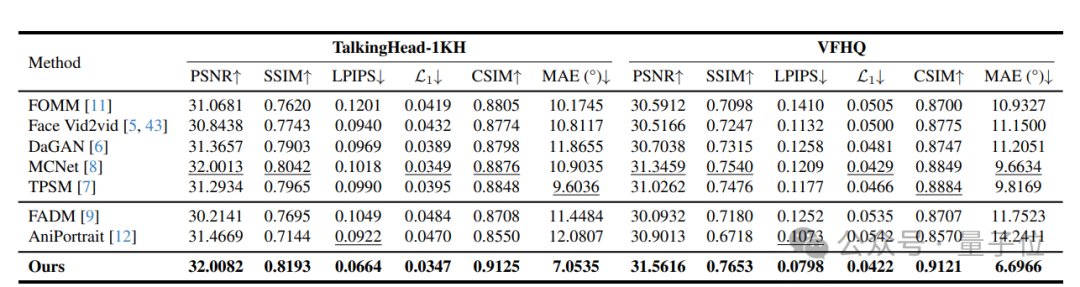
快手可灵团队最新开源项目火了:大叔变身少女,GitHub狂揽7.5K星
18
0
相关文章
近七日浏览最多
标签云
github
微软
搜索引擎
品牌影响力
rtx
ipad
mac
斯坦福大学
特斯拉
斯坦福
人工智能
arm
科技
oled
蚂蚁集团
华为云
腾讯
chris
rain
安卓
linux
ui
alex
隐藏功能
纽约时报
黑客
华尔街日报
苹果
pilot
chro
谷歌
美元
智能眼镜
任天堂
游戏
switch
互联网时代
微星
芯片
非公版
系列显卡
nvidia
显存
美光
英伟达
显卡
gpu
英特尔
ows
adobe
波音公司
波音
航空航天
三星
智能手机
经济日报
元气满满
抖音
ces
x50
锐龙
处理器
七彩虹
火星
ultra
华硕
kimi
hdr
npu
cuda
雾山五行
pdd
发动机
中国航空
美国政府
f35战斗机
萨博
北约
马丁
爱国者
导弹
雷神
火箭发动机
乌克兰
美联储
美股