白交 发自 凹非寺
量子位 | 公众号 QbitAI
澜舟科技官宣:孟子3-13B大模型正式开源!
这一主打高性价比的轻量化大模型,面向学术研究完全开放,并支持免费商用。

在MMLU、GSM8K、HUMAN-EVAL等各项基准测评估中,孟子3-13B都表现出了不错的性能。
尤其在参数量20B以内的轻量化大模型领域,在中英文语言能力方面尤为突出,数学和编程能力也位于前列。

据介绍,孟子3-13B大模型是基于Llama架构,数据集规模高达3T Tokens。
语料精选自网页、百科、社交、媒体、新闻,以及高质量的开源数据集。通过在万亿tokens上进行多语言语料的继续训练,模型的中文能力突出并且兼顾多语言能力。
孟子3-13B大模型开源
只需两步,就能使用孟子3-13B大模型了。
首先进行环境配置。
pip install -r requirements.txt
然后快速开始。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizertokenizer = AutoTokenizer.from_pretrained("Langboat/Mengzi3-13B-Base", use_fast=False, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained("Langboat/Mengzi3-13B-Base", device_map="auto", trust_remote_code=True)inputs = tokenizer('指令:回答以下问题。输入:介绍一下孟子。输出:', return_tensors='pt')if torch.cuda.is_available():inputs = inputs.to('cuda')pred = model.generate(**inputs, max_new_tokens=512, repetition_penalty=1.01, eos_token_id=tokenizer.eos_token_id)print(tokenizer.decode(pred[0], skip_special_tokens=True))此外,他们还提供了一个样例代码,可用于基础模型进行单轮交互推理。
cd examples
python examples/base_streaming_gen.py --model model_path --tokenizer tokenizer_path如果想要进行模型微调,他们也提供了相关文件和代码。
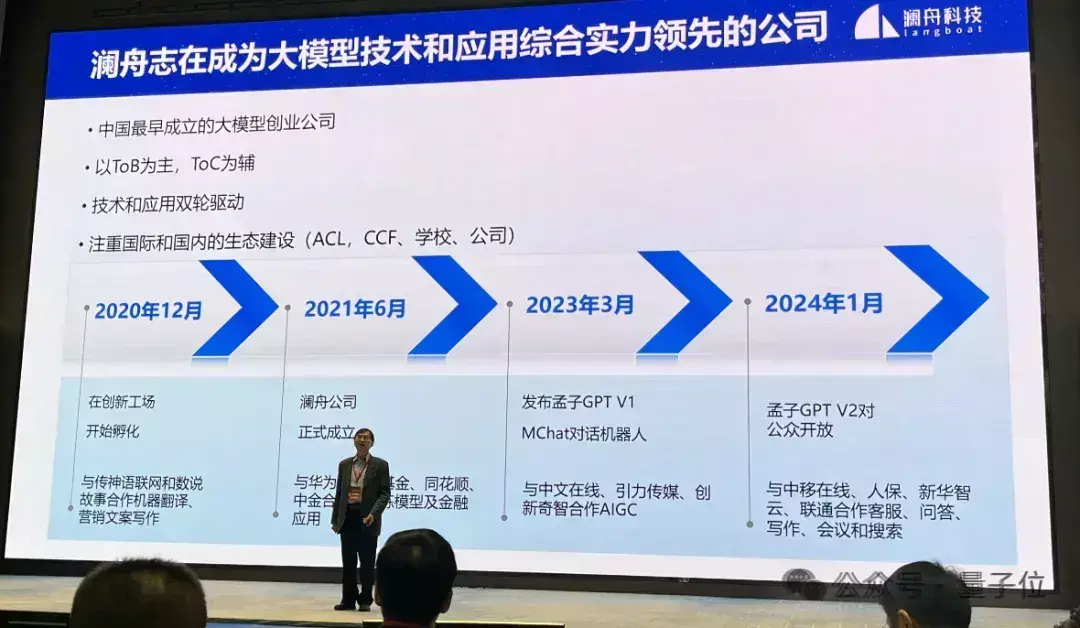
事实上,早在3月18日的澜舟大模型技术和产品发布会现场,就透露了孟子3-13B大模型的诸多细节。
当时他们表示,孟子3-13B大模型训练已经完成。
对于选择13B版本的原因,周明解释道:
首先,澜舟明确以服务ToB场景为主,ToC为辅。
实践发现,ToB场景使用频率最高的大模型参数量多为7B、13B、40B、100B,整体集中在10B-100B之间。
其次,在这个区间范围内,从ROI(投资回报率)角度来讲,既满足场景需求,又最具性价比。
因此,在很长一段时间内,澜舟的目标都是在10B-100B参数规模范围内,打造优质的行业大模型。
作为国内最早一批大模型创业团队,去年3月,澜舟就发布了孟子GPT V1(MChat)。
今年1月,孟子大模型GPT V2(含孟子大模型-标准、孟子大模型-轻量、孟子大模型-金融、孟子大模型-编码)对公众开放。
好了,感兴趣的朋友可戳下方链接体验一下。
GitHub链接:
https://github.com/Langboat/Mengzi3HuggingFace:https://huggingface.co/Langboat/Mengzi3-13B-BaseModelScope:https://www.modelscope.cn/models/langboat/Mengzi3-13B-BaseWisemodel:https://wisemodel.cn/models/Langboat/Mengzi3-13B-Base—完—
@量子位 · 追踪AI技术和产品新动
深有感触的朋友,欢迎赞同、关注、分享三连վ'ᴗ' ի ❤态
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com