



友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
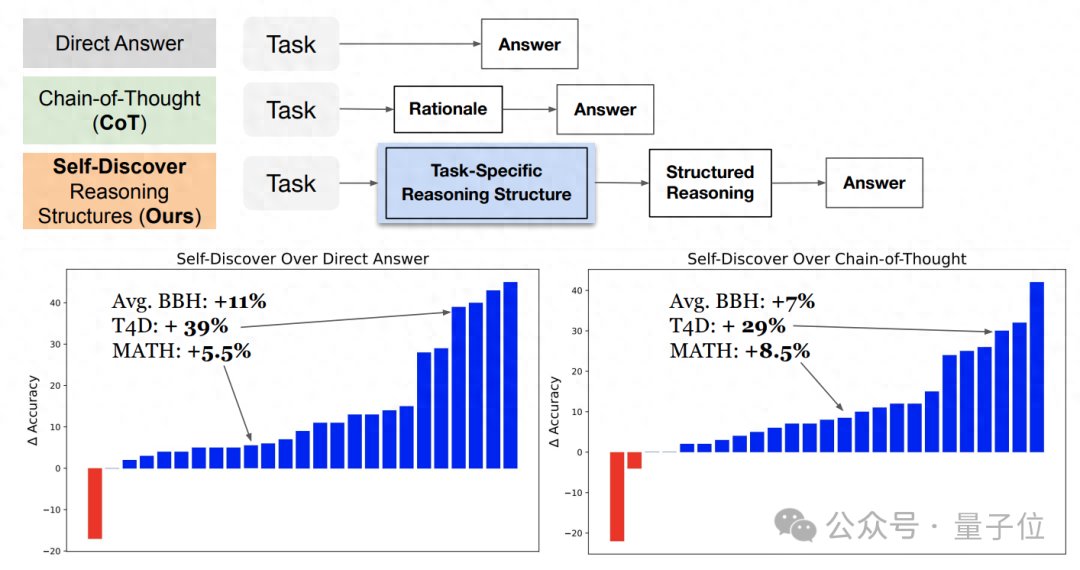
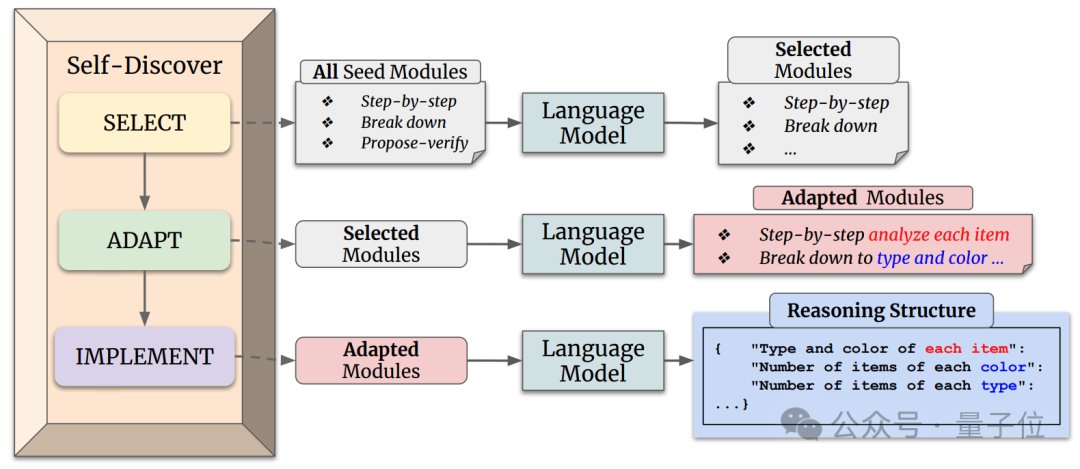
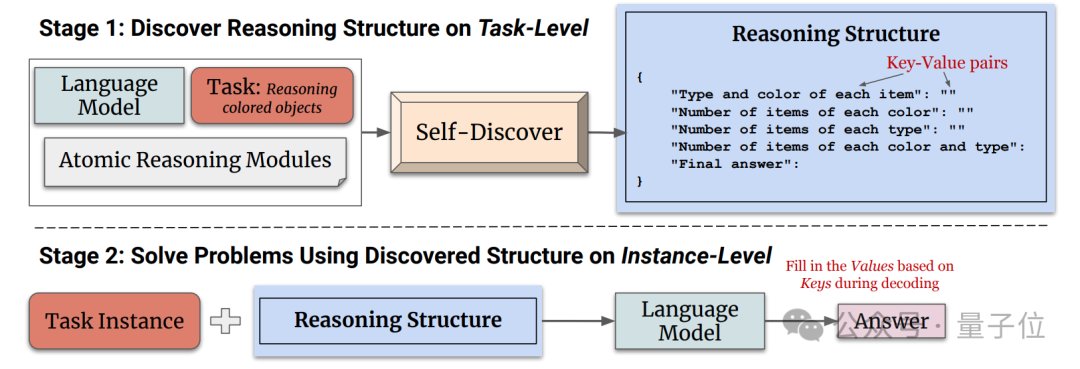
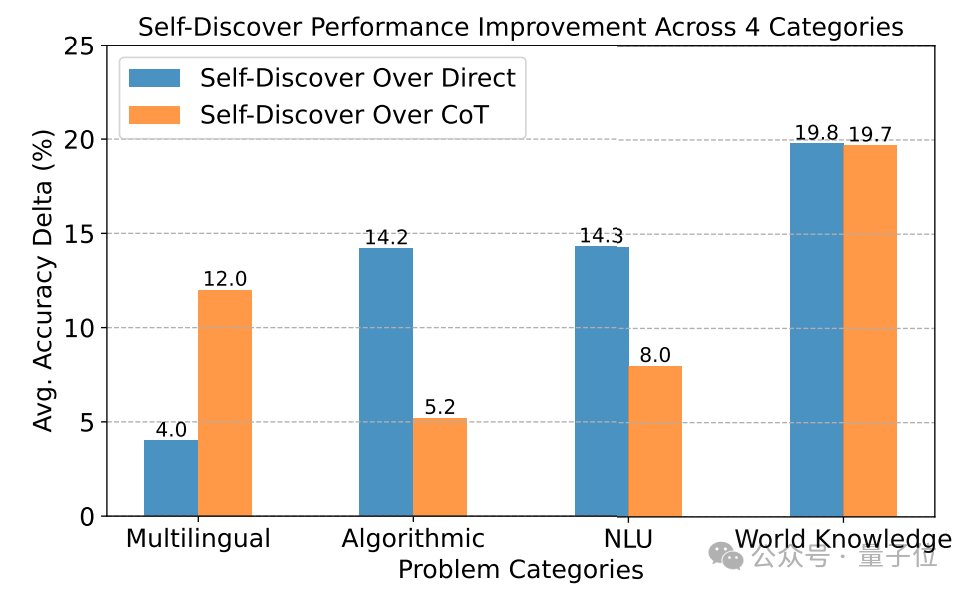
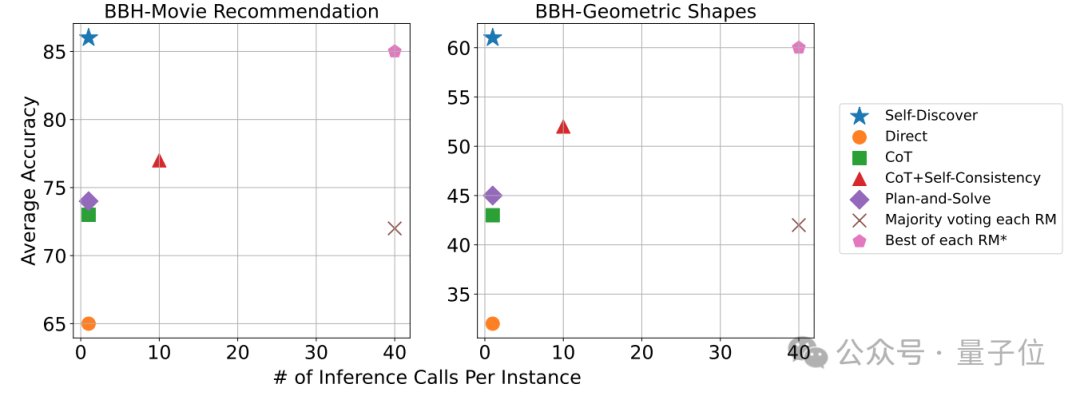
GPT-4推理能力暴涨32%,谷歌新型思维链效果超CoT,成本降至1/40
51
0
相关文章
近七日浏览最多
最新文章
标签云
nlp
操作系统
人工智能
股票
科技
万军伟
初创公司
蔡崇信
kimi
腾讯
融资
机器人
科大讯飞
毛利率
时代周报
陆金所
云计算
湖南大学
阿里云
华为公司
盘古
华为
复旦大学
高考
ios
苹果
阿里巴巴集团
阿里
世界500强
tpms
科协
达芬奇
小红书
快科技
鸿蒙
ipad
小米手机
ipo
金融界
3d建模
matebook
哈尔滨工业大学
哈工大
人工智能专业
天使轮
纳指
谷歌
苹果公司
标普指数
知名企业
Google
特斯拉公司
微软
黄仁勋
amd
超威半导体
英伟达芯片
deepseek
墨西哥湾
墨西哥政府
墨西哥总统
唐纳德特朗普
美国总统特朗普
霸权
美国湾
外交部
苹果地图
美国政府
安卓系统
智能手机
人民日报
apple
百度
中国
李彦宏
英伟达股价
立案
热点
市场监管总局
美国
舆论战
网络攻击
科技巨头
春节保卫战
奇虎360
行政令
唐纳川普
OpenAI
翻译
颜文字
文言文
tiktok
应用程序
特朗普
应用商店
网络浏览器
gpu
亚马逊
字节跳动
罗杰施密特
美国广播公司
首席执行官
台积电
显卡
垄断
芯片
烟草
英伟达
特斯拉
科技股
美股
收盘
道指
微芯片
量子计算机
埃隆_马斯克
量子计算芯片
奥特曼游戏
宇宙
量子革命
超级计算机
佩斯科夫
俄罗斯政府
广播公司
youtube
俄罗斯
李世石
阿尔法狗
哈萨比斯
诺贝尔奖
alphago
安卓
人社局
路透社
苹果手机
华为手机
国产手机
三折叠屏手机
iphone
微信
美国司法部
美元
chro
ibm
李开复
siri
世界知识
克拉夫特
克苏鲁
游戏
ps5
自动驾驶
智能汽车
pilot
思维方式
加州大学
牛顿
直播
宇航员
外星人
英国
骑自行车
包青天
包拯
福气
你的生活
不能说的秘密
大学期间
女运动员
化妆
心理健康
最强大脑
黄金时间
霍启刚
人的价值
郭晶晶
出轨
大众
股价
价值投资
长相思
学生时代
马斯克
天蝎座
狮子座
星座
双子座
图书馆
口腔溃疡
跟着我一起
今日头条
我们这一代
统一六国
唐太宗李世民
藏獒
印度
余承东
北大
北京大学
人际关系
双鱼座
射手座
市场营销
运势
白羊座
摩羯座
金牛座
处女座
雪姨
依萍
陆振华
情深深雨濛濛
教育部
共和党
美国总统
白宫新闻秘书
张艺谋
巩俐
espn
安东尼
布鲁克
卡梅隆
甜瓜
鲸鱼
戴维斯
东方雨虹
北向资金
贾斯汀
美国高中
etf
基金经理
中证500
shams
骨质疏松症
nature
哺乳期
rain
红高粱
许雅钧
大s
小s
吊带
平行宇宙
希腊
美国大学
是真的吗
肝癌
鳄鱼
癌症
红酒
口腔癌
老年人
科学进展
研究所
布朗尼
詹姆斯
湖人队
湖人
勒布朗
希金斯
nba
凯尔特人
尼古拉
许曦文
美国南
身材高挑