
编译 | ZeR0编辑 | 漠影
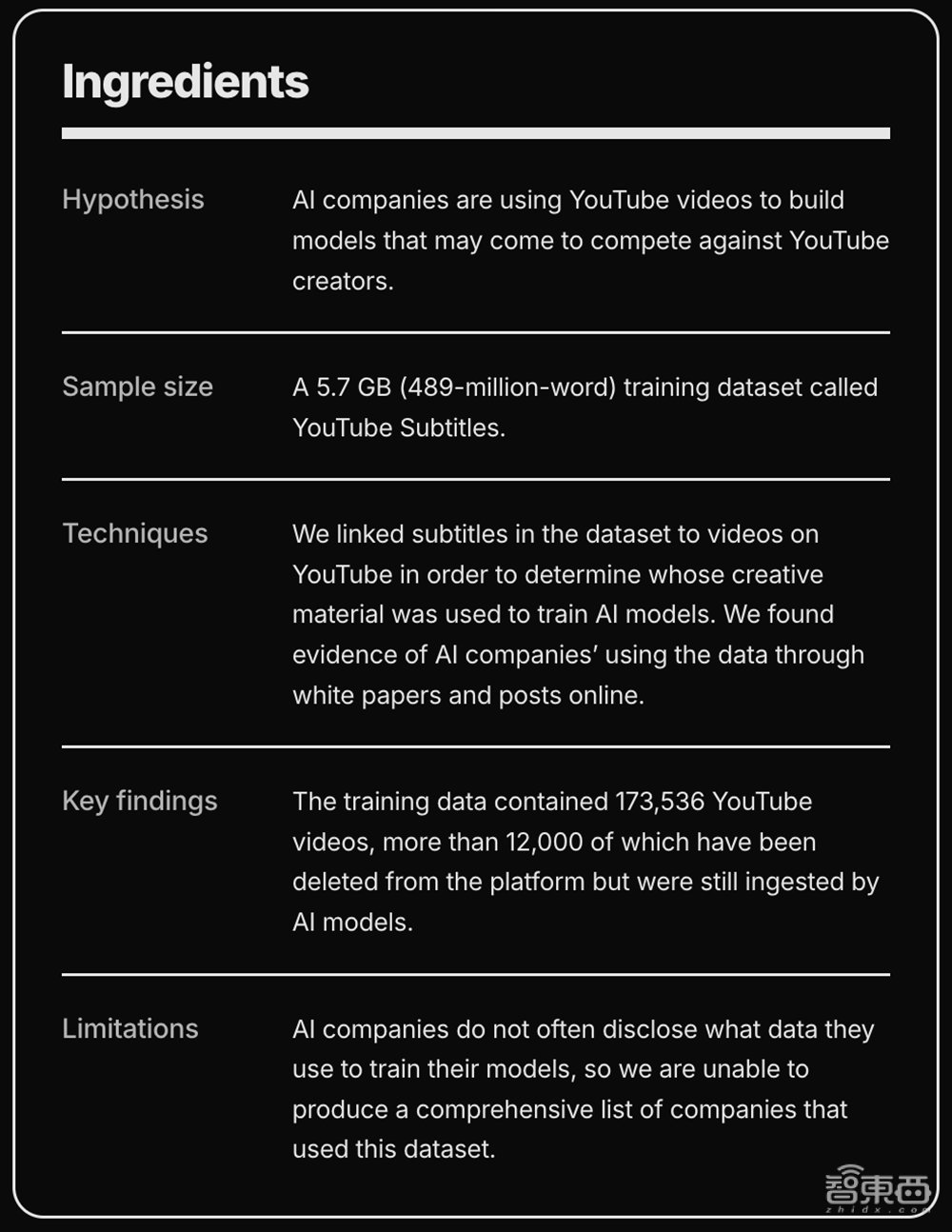
智东西7月17日消息,Proof News的一项最新调查发现,从超过48,000个频道窃取的173,536个YouTube视频的字幕被Anthropic、英伟达、苹果、Salesforce等硅谷巨头使用。
这些一些全球最有钱的AI公司已经使用成千上万个YouTube视频中的素材来训练人工智能(AI)。尽管YouTube规定禁止未经许可从该平台获取素材,但这些公司还是这样做了。
这个名为YouTube字幕(YouTube Subtitles)的数据集包含了来自可汗学院、麻省理工学院和哈佛大学等教育和在线学习频道的视频文本。《华尔街日报》、美国国家公共电台和英国广播公司的视频均被用来训练AI,《斯蒂芬·科尔伯特深夜秀》、《约翰·奥利弗上周今夜秀》和《吉米·坎摩尔秀》也是如此。
Proof News还发现了来自YouTube巨星的素材,包括MrBeast(2.89亿订阅者,2个视频被用于训练)、 Marques Brownlee(1900万订阅者,7个视频被)、 Jacksepticeye(近3100万订阅者,377个视频)和PewDiePie(1.11亿订阅者,337个视频)。一些用于训练AI的素材还宣扬了“地平说”等阴谋论。
一、YouTube素材被科技巨头用于训练AI,创作者毫不知情
Proof News创建了一个工具来在YouTube AI训练数据集中搜索创作者。
“没有人来找我说‘我们想用这个’。”大卫·帕克曼(David Pakman)说道。《大卫·帕克曼秀》是一个偏左的政治频道,有200多万订阅者和20多亿次观看量。他的近160个视频被纳入YouTube字幕训练数据集。
帕克曼的企业有4个全职员工,除了制作播客、TikTok视频和其他平台的素材外,该公司每天还会发布多个视频。帕克曼说,如果AI公司获得报酬,那么他应该因使用自己的数据而获得补偿。此前一些媒体公司最近签署了协议,同意因使用他们的工作来训练AI而获得报酬。
“这是我的生计,我投入了时间、资源、金钱和员工时间来创作这些内容,”帕克曼说,“真的不缺工作。”
“这是盗窃。”流媒体服务Nebula的首席执行官戴夫·威斯库斯(Dave Wiskus)认为。Nebula的部分股权由其创造者所有,其中一些创造者的作品被从YouTube上盗用,用来训练AI。
在他看来,未经创作者同意使用他们的作品是“不尊重”的行为,尤其是工作室可能会“使用生成式AI来尽可能多地取代艺术家”。
“这会被用来剥削和伤害艺术家吗?是的,绝对会的。”威斯库斯说。
该数据集的创建者EleutherAI的代表没有回应对Proof调查结果的置评请求,包括对未经许可使用视频的指控。该公司的网站表示,其总体目标是降低AI开发的门槛,让那些身处科技巨头之外的人能够参与其中,该公司历来“通过训练和发布模型,让大家接触到尖端的AI技术”。
YouTube字幕不包含视频图像,而是由视频字幕的纯文本组成,通常还附带日语、德语和阿拉伯语等语言的翻译。
根据EleutherAI发表的研究论文,该数据集是该非营利组织发布的名为Pile的汇编的一部分。Pile的开发者不仅收集了YouTube的材料,还收集了欧洲议会、英语维基百科以及安然公司员工的大量电子邮件,这些电子邮件是联邦政府对该公司进行调查时发布的。
Pile的大部分数据集都是开放的,任何拥有足够空间和计算能力的人都可以在互联网上访问。学术界和大型科技公司以外的其他开发人员利用了该数据集,但他们并不是唯一的利用者。
市值数千亿甚至数万亿美元的苹果、英伟达、Salesforce等公司在其研究论文和帖子中描述了如何使用Pile训练AI。
文件还显示,苹果使用Pile训练OpenELM,这是一个备受瞩目的模型,于4月发布,几周后该公司宣布将为iPhone和MacBook添加新AI功能。
相关出版物显示,彭博和Databricks也在Pile上训练模型。
明星AI大模型独角兽Anthropic同样如此,它从亚马逊获得了40亿美元的投资,并强调其对“AI安全”的关注。
Anthropic发言人Jennifer Martinez在一份声明中称:“The Pile只包含一小部分YouTube字幕。”该声明证实Anthropic的生成式AI助手Claude 使用了Pile,“YouTube的条款涵盖了其平台的直接使用,这与使用The Pile数据集不同。关于可能违反YouTube服务条款的问题,建议问The Pile的作者。”
Salesforce证实将使用Pile构建AI模型,用于“学术和研究目的”。Salesforce AI研究副总裁Caiming Xiong在一份声明中强调,该数据集是“公开可用的”。
Salesforce后来在2022年发布了相同的AI模型供公众使用,根据其Hugging Face页面显示,该模型自发布以来已被下载至少86,000次。
Salesforce开发人员在他们的研究论文中指出,Pile包含亵渎性语言以及“对性别和某些宗教群体的偏见”,并警告说这可能会导致“漏洞和安全问题”。Proof News在YouTube字幕中发现了数千个亵渎性语言的例子,以及种族和性别辱骂的例子。
Salesforce的代表没有回应有关安全问题。英伟达的一位代表拒绝发表评论。苹果、Databricks、彭博社的代表均未回应置评请求。
二、YouTube数据“金矿”
巴西里约热内卢热图利奥·巴尔加斯基金会法学院人工智能政策研究员兼CyberBRICS研究员杰·维普拉(Jai Vipra)认为,AI公司相互竞争,部分原因在于获取更高质量的数据。这是公司对数据来源保密的原因之一。
今年早些时候,《纽约时报》报道称,YouTube母公司谷歌利用该平台上的视频作为文本来训练其模型。对此一位发言人告诉该报,根据与YouTube创作者的协议,谷歌被允许使用这些文本。
《纽约时报》的调查还发现,OpenAI未经授权使用了YouTube视频。该公司代表既没有证实也没有否认该论文的调查结果。
OpenAI高管曾多次拒绝公开回答有关其是否使用YouTube视频来训练其AI产品Sora(该产品可根据文本提示制作视频)的问题。今年早些时候,《华尔街日报》向OpenAI首席技术官米拉·穆拉蒂提出了这个问题,穆拉蒂回答说:“我实际上并不确定。”
在维普拉看来,YouTube字幕和其他类型的语音转文本数据可能是一座“金矿”,因为它们可以帮助训练模型来复制人们说话和交流的方式。
“这仍然是纯粹的原理问题。”《戴夫教授讲解》的主持人戴夫·法里纳(Dave Farina)说。他的频道展示化学和其他科学教程,拥有 300万订阅者,并有140个视频被盗用YouTube字幕。
他说:“如果你从我所做的工作(制造产品)中获利,而这却会让我失业或让我这样的人失业,那么就需要就补偿或某种监管进行讨论。”
YouTube字幕数据集于2020年发布,其中还收录了12,000多个视频的字幕,这些视频现已从YouTube上删除。至少有一个案例中,创作者删除了他们的整个在线信息,但这项工作已被纳入了数量不详的 AI 模型中。
Proof News尝试联系本报道中提到的频道所有者。许多人没有回应置评请求。在其采访的创作者中,没有人意识到他们的信息被窃取了,更不用说这些信息是如何被使用的了。
令人惊讶的是:Crash Course(近1600万订阅者,871个视频)和SciShow(800万订阅者,228个视频)的制作人,它们是汉克和约翰·格林兄弟的教育视频帝国的支柱。该节目制作公司Complexly的首席执行官朱莉·沃尔什·史密斯(Julie Walsh Smith)在一份声明中称:“我们精心制作的教育内容在未经我们同意的情况下被以这种方式使用,我们对此感到非常沮丧。”
YouTube字幕并不是第一组给创意产业带来麻烦的AI训练数据。
Proof News撰稿人亚历克斯·赖斯纳(Alex Reisner)获得了Pile的另一个数据集Books3的副本,并于去年在《大西洋月刊》上发表了一篇文章,报告了他的发现:超过18万本书被窃取,其中包括玛格丽特·阿特伍德、迈克尔·波伦和扎迪·史密斯的作品。
此后,许多作家起诉AI公司未经授权使用他们的作品并涉嫌侵犯版权。类似案件如滚雪球般越滚越大,托管Books3的平台已将其下架。
针对这些诉讼,Meta、OpenAI、彭博社等被告辩称,他们的行为构成了合理使用。原告主动撤回了针对最初抓取书籍并公开的EleutherAI的诉讼。
其余案件的诉讼仍处于早期阶段,许可和付款问题尚未解决。The Pile已从其官方下载网站删除,但仍可在文件共享服务上获取。
“科技公司一直粗暴地对待我们。”消费者保护律师、DiCello Levitt律师事务所合伙人艾米·凯勒(Amy Keller)说,她曾代表创意人士提起诉讼,指控他们的作品在未经同意的情况下被AI公司窃取。
“人们担心自己在这件事上别无选择,”凯勒谈道,“我认为这才是真正的问题所在。”
三、“鹦鹉学舌”
许多创作者对于未来的道路感到迷茫。
全职YouTube博主会巡查其作品是否被未经授权使用,并定期发送删除通知,有些人担心,AI生成与他们的作品类似的内容只是时间问题。
《大卫·帕克曼秀》的创作者帕克曼最近在浏览TikTok时看到了AI的威力。他偶然发现了一段被标记为塔克·卡尔森剪辑的视频,但当帕克曼观看时,他大吃一惊——这段视频听起来像卡尔森的,但逐字逐句都和帕克曼在YouTube节目上说的一样,甚至连节奏都一样。
同样让他感到震惊的是,只有一位视频评论者似乎意识到这是假的——一个语音克隆的卡尔森声音读了帕克曼的剧本。
“这会是个问题,”帕克曼在一段有关假货的YouTube视频中说,“基本上你可以对任何人这样做。”
EleutherAI创始人希德·布莱克(Sid Black)在GitHub上写道,他使用脚本创建了YouTube字幕。该脚本从YouTube的API下载字幕,方式与YouTube观众在观看视频时浏览器下载字幕的方式相同。
根据GitHub上的文档,布莱克使用了495个搜索词来筛选视频,包括“搞笑视频博主”、“爱因斯坦”、“黑人新教徒”、“保护性社会服务”、“信息战争”、“量子色动力学”、“本·夏皮罗”、“维吾尔族”、“果食主义者”、“蛋糕食谱”、“纳斯卡线条”和“地球是平的”。
尽管YouTube的服务条款禁止通过“自动方式”访问其视频,但超过2000名GitHub用户已收藏或认可该代码。
机器学习工程师乔纳斯·德泊伊克斯(Jonas Depoix)在GitHub上的讨论中写道:“如果YouTube想要阻止该模块运行,他们有很多方法可以做到。”他在GitHub上发布了布莱克用来访问YouTube字幕的代码,“到目前为止,这种情况还没有发生。”
在给Proof News的一封电子邮件中,德泊伊克斯称,自从几年前他在大学期间为一个项目编写了这段代码后,他就再也没有使用过它,他很惊讶人们竟然觉得它很有用。他拒绝回答有关YouTube规则的问题。
谷歌发言人杰克·马龙(Jack Malon)在回复置评请求的电子邮件中表示,该公司“多年来一直采取行动,防止未经授权的滥用数据抓取行为”。他没有回答有关其他公司使用这些材料作为训练数据的问题。
AI公司使用的视频中,有146个来自“爱因斯坦鹦鹉”频道,该频道拥有近15万订阅者。非洲灰鹦鹉的饲养员玛西娅不愿透露自己的姓氏,因为担心会危及这只著名鸟类的安全。她说,起初她觉得AI模型竟然能记住一只模仿鹦鹉的话语很有趣。
“谁会想用鹦鹉的声音?”玛西娅说,“但我知道他说得很好。他用我的声音说话。所以他在模仿我,然后AI在模仿鹦鹉。”
一旦被AI吸收,数据就无法被遗忘。玛西娅担心她的鹦鹉信息可能会被以各种未知方式利用,包括创建一只数字复制鹦鹉,她担心的是,这只鹦鹉可能会骂人。
“我们正在踏入未知领域。”玛西娅说道。
来源:Proof
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com