全民Long-LLM时代终于到来。
本月,中国初创AGI(通用人工智能)公司月之暗面宣布旗下大模型工具Kimi Chat正式升级到200万字参数量,与五个月前该大模型初次亮相时的20万字相比,提升十倍。Kimi Chat的升级彻底引爆市场,同时也引起长文本大模型(Long-LLM)细分赛道更加激烈的竞争。

(图源:阿里 通义千问)
昨日,阿里旗下的大模型工具通义千问宣布迎来重磅升级,向所有人开放最高1000万字的长文本处理能力,更重要的是,这项升级完全免费。此项升级对于专业领域的意义重大,例如金融、医疗、科研等从业人员,都能利用这项功能更快速地提取出核心关键词,节省文档归整、资料整理的时间。
不仅是阿里,百度文心一言也迎来了长文本处理能力的升级。据官方资料显示,文心一言将在下个月开放免费的200万-500万字长文本处理功能,较此前最高2.8万字的文档处理能力提升上百倍。
此外,360也在本月正式上线了360 AI搜索,通过大模型重塑,结合长文本技术在海量搜索结果中理解并生成精准的答案提供给用户。而这款APP,也同样是完全免费的。

(图源:TechTalks)
长文本一直以来都是大模型工具「内卷」的方向,如何在超百万字的文档里做出有效的信息整理、观点归纳,都是技术上的难点。当然,正如半导体行业与消费电子产品市场之间的关系一样,很多消费者能感受到手机、电脑等产品性能正在飞跃式成长,但落实到实际体验上,似乎没有太多的变化。
而在生成式人工智能(GenAI)领域里,「卷」参数会是一个虚无缥缈的噱头,还是造福人类的行为,还很难回答。
大模型是如何拿下长文本技术的?
在弄清楚「卷」参数到底有何意义之前,我们首先需要了解AI企业们到底在「卷」什么东西。
与衡量手机性能以跑分分数为准一样,大模型也有属于自己的「性能基准」——token,这是一个大模型专用的输入、输出基本单位。在OpenAI给出的准则里,1k token等于750个英文单词、500个中文汉字。
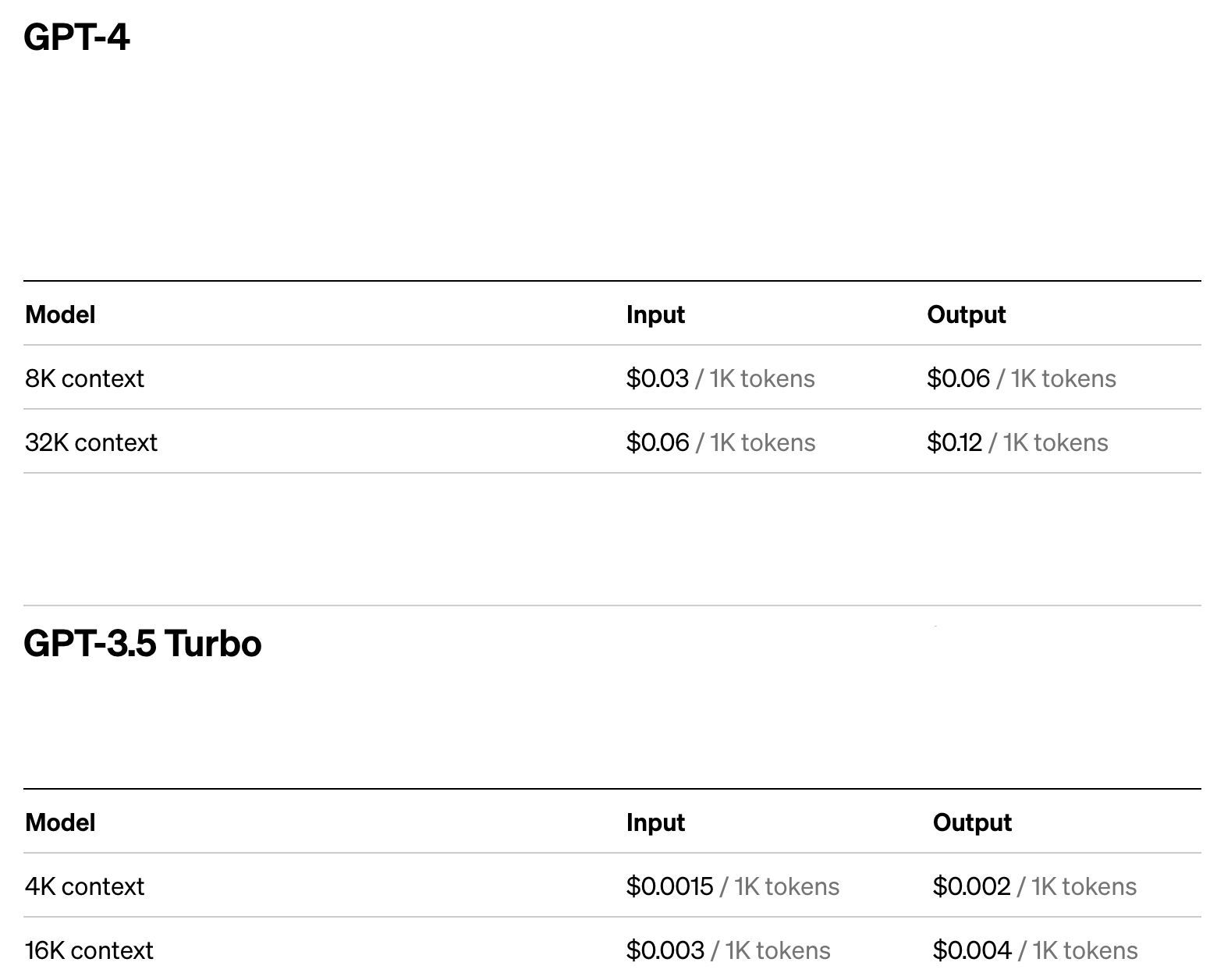
(图源:OpenAI)
同理,token数字越大,能够处理的内容篇幅就越长。ChatGPT-4目前的参数量为8k-32k token、Anthropic公司推出的Claude为100K token,而中国初创企业月之暗面推出的Kimi Chat则是达到了惊人的400K token。具体到实例,Kimi Chat能够在20秒左右读完1篇20万字的长篇小说、通文千义也能在数秒时间里读完80万字的《三体》。
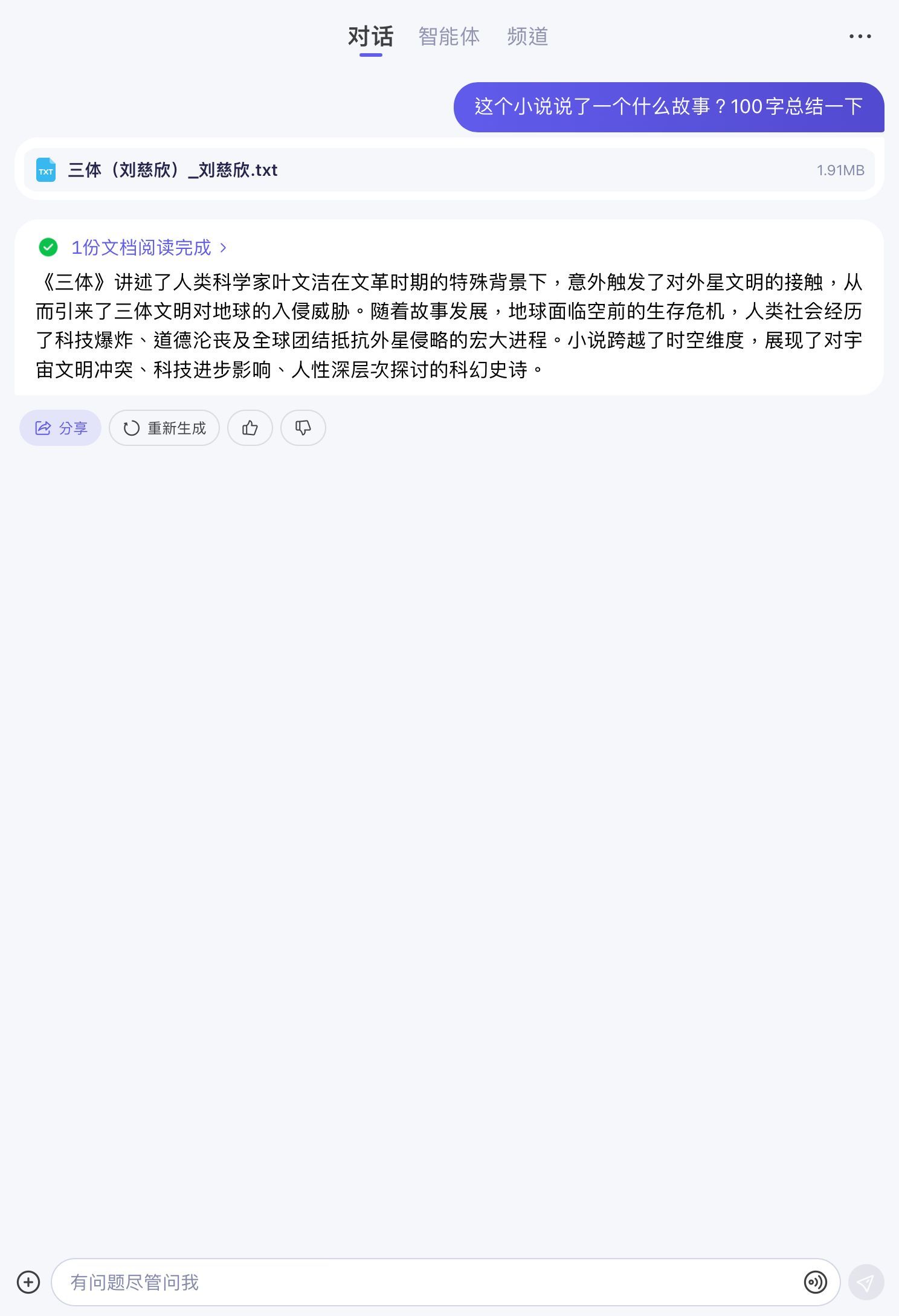
(图源:雷科技制图/通义千问)
参数量剧增所带来的好处自然是大模型对于更长的内容拥有更快速的理解能力,这能够帮助用户从中提炼到所需的摘要、信息点,又或是直接生成整篇内容的总结。语言大模型之所以能够快速「引爆」整个市场,正是得益于这种速度惊人的理解能力。

(图源:雷科技制图/Kimi Chat)
但要彻底攻克长文本,大模型光靠堆砌token参数量并不能完全解决这个问题。超大数量的token的确能够快速阅读完长文档,但段落与段落间的内容也更容易出现「断裂」的情况,这与缺少模型的预先训练有关。目前拥有超大token的AI方案提供商,通常在Transformer预测词之前投喂词元模型,使整体结论更加完整。

(图源:Code-Llama)
比如Code-Llama,标称16K token参数量,但实际上是由一个个4K token窗口连接而成,最终产生出16k token总模型。而这就十分考验大模型工具在窗口之间的推理能力。试想一下,在专业领域中,长文内容都有紧密的逻辑性与关联性,假如大模型推理失误,则有可能出现最终生成的摘要牛头不对马嘴,这对于大模型工具的商业、个人应用,都是致命的打击。
当然,大模型的推理能力是可以通过训练得到进步的,这就不难解释为何阿里、百度都选择优先将长文本模型功能免费开放给个人用户,毕竟更多用户加入,模型推理能力的进化速度才能加快。
(图源:百度 文心一言)
但免费应用也是一件好事情,长文本的快速阅读一直以来也是用户在大模型各项实际应用场景最关注的一项,比如正在写毕业论文的学生党,可能将超长的论文喂给大模型工具,让其快速提炼、总结,甚至找出论文中的研究结论。
长文档能力拓展,用途比我们想象中要多
阿里的通义千问将长文本档能力的拓展方向瞄准在专业领域的内容理解上,尤其是金融、医学等,对于这些行业的从业人员而言,从前需要花上几天或是十几天才能读完的文章,如今只需花上十几秒就能看完其中的精华之处。
但大模型长文本的能力远不止于此。
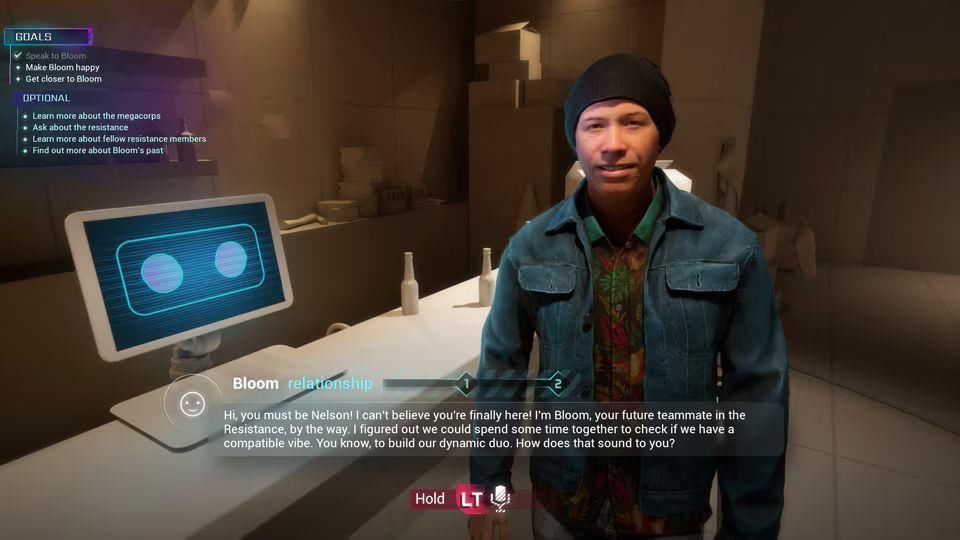
(图源:育碧)
不久前,知名游戏公司育碧公开的全新「NEO NPC」技术,正是Long-LLM(长文本大模型)升级后衍生的新方向。众所周知,3A游戏大作的灵魂往往与其精彩的剧本离不开关系,其中各式各样的游戏角色,也因其丰富的背景故事和鲜明的个性深受玩家喜好。大模型从1k token进化到100k token,甚至是400k token,能够让游戏剧本完整地覆盖到每个游戏角色里,让他们的对话、行为,既符合游戏的世界观,又能保证一定的灵活性。
这项能力同样可以应用在我们生活中最离不开的功能——搜索。
(图源:雷科技制图/360AI 搜索)
本月初,360在北京举行了一场活动,旗下全新360 AI 搜索和360 AI 浏览器率先亮相。360 AI 搜索的核心在于“理解”、“提炼”、“总结”,即抛开传统搜素引擎将所有与之相关的内容为用户一一呈现的做法,主动介入搜索结果,在数以万计的匹配信息里提炼出最有效的信息。
360 AI 浏览器则是变成彻底的「AI工具」。周鸿祎解释道,360 AI 浏览器的定位是学习、生产力工具,它能帮助用户快速阅读书籍、文章,了解视频内容等。此外,360 AI 浏览器未来还将拥有续写功能,这同样基于大模型长文档的理解。
更重要的是,更长的文档内容理解有助于加速AI快速过渡到AGI(通用大模型)时代。正如前文所说,Long-LLM较之前最大的变化在于对超长文本的理解、记忆、总结能力,这些能力可以是大模型更加「拟人」,即记住样本的真实喜好从而判断其行为,又或是根据真实世界的物理规则,生成完全符合实际的内容。
Long-LLM能改变世界,但算力难以解决
早在去年底,大模型长文本技术就已经进入到火热阶段,但却鲜有AI企业将这项技术应用到大模型工具中,更别提免费向大众开放了。
OpenAI CEO Altman在接受公开访问时也表示,由于算力不足,GPT-4的32K token短期内无法向大众开放。要知道,OpenAI可是当前人工智能市场里获投资最高的头部企业之一,连它都空有技术却无法落地,不免让人对Long-LLM的未来感到担忧。
在算力不足的前提下有没有办法「投机取巧」呢?当然有。
目前主流节省算力的长文本技术通常有三种,分别是短文档重复检索、内容分组检索和模型本身的优化。前两种方案在技术原理上相对一致,都是将重复的内容进行「记忆」,节省理解时间,减少算力消耗;而模型本身的优化则要复杂许多,相当于用短文档推导出长文档,这非常考究模型本身的结构优化。

(图源:英伟达)
在当前,算力仍是阻碍Long-LLM成长的一大关键因素,但随着英伟达、英特尔等硬件供应商不断加码,这项技术在未来也将成为AI领域发展的风向标之一。
写在最后
如果说OpenAI的Sora展现出其在AGI时代关于视频领域上的想象,那么Long-LLM则是奔向全场景通用智能的基桩。
大模型长文本技术能让AI助手记住用户的所有你与它谈论过的话题,这让你们之间能够创造真实的回忆,而不是像从前一样,在开始新对话之后,前面的「AI」就忘记了刚刚发生过的任何事情。这使得它能够变成更好的AI智能客服,毕竟即便是真人,也难以记住与每位咨询者发生过的对话。同样的,Long-LLM还能化身数字人主播、创造数字偶像等等。
或许,在大模型长文本技术的支持下,AGI时代将在不久后真正到来。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com